Logical reasoning tests for hiring | types & how to use them
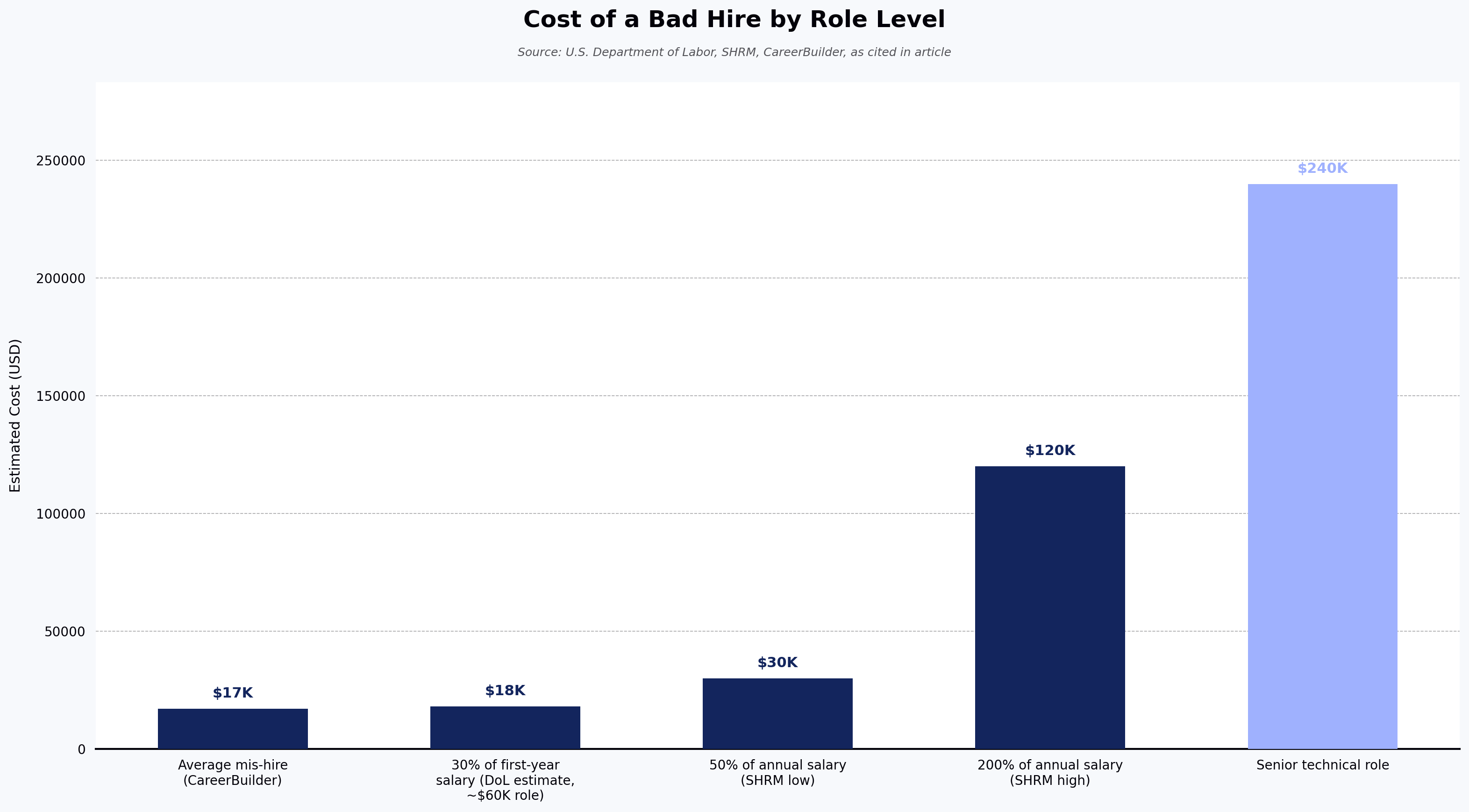
Logical reasoning tests are among the most research-backed pre-employment tools available for predicting on-the-job performance, and most hiring teams still are not using them well. A logical reasoning test measures how a candidate analyzes information, identifies patterns, and reaches valid conclusions — the cognitive work that drives real performance in technical, analytical, and management roles. The case for adopting them is grounded in cost as much as accuracy. The U.S. Department of Labor has estimated a mis-hire costs at least 30% of that employee's first-year salary, while SHRM puts the full replacement cost between 50% and 200% of annual salary. A widely cited CareerBuilder survey reported that nearly 75% of employers had made at least one bad hire, with an average reported loss around $17,000 per incident. For senior technical roles, industry reporting suggests those figures can climb to $240,000 or more.
Resumes and unstructured interviews remain the default for most hiring teams, but neither predicts on-the-job performance well. Resumes measure credential accumulation. Unstructured interviews measure how well someone interviews. Logical reasoning tests measure something more fundamental: how a person actually thinks.
What is a logical reasoning test?
Most pre-employment tools measure what a candidate knows or has done. Logical reasoning tests measure how they think, which turns out to be a much better predictor of what they will do when a new problem lands on their desk.
A logical reasoning test is a standardized pre-employment assessment that measures a candidate's ability to analyze information, identify patterns, evaluate arguments, and draw valid conclusions, without relying on specialized or domain-specific knowledge. The candidate works through premises, sequences, diagrams, or argument passages and must apply structured thinking to arrive at the correct answer. Unlike a personality test or a skills assessment, it does not care where someone went to school or what tools they have used. It isolates the underlying cognitive processes that drive problem-solving in any context.
The research supporting their use has among the strongest predictive validity records in pre-employment assessment research. The Schmidt and Hunter (1998) meta-analysis, cited more than 6,500 times in I-O psychology, demonstrated that general mental ability is one of the most consistent predictors of job performance across industries. Predictive validity reaches r = 0.56 for high-complexity roles like engineering and management. Paired with a structured interview, composite validity climbs above 0.60, among the highest of any hiring method available.
Why employers use logical reasoning tests
- Scoring is more consistent than unstructured interviews, which reduces interviewer bias and enables fairer comparison across a diverse candidate pool
- A single assessment can screen hundreds of applicants simultaneously, which matters at volume
- Strong predictive validity for engineering, analytics, product, and consulting roles where novel problem-solving is constant
- Early-funnel filtering cuts time-to-hire by surfacing qualified candidates before recruiter time is spent
- Cognitive assessments are increasingly standard in skills-based hiring programs across industries
According to a 2025 TestGorilla skills-based hiring report, 85% of companies globally now use skills-based hiring that includes cognitive assessments, up from 73% in 2023, and 88% reported a measurable reduction in mis-hires. Industry surveys also suggest that organizations using pre-employment assessments commonly report improvements in quality of hire, although the specific percentage varies by study.
Types of logical reasoning tests
Picking the wrong test type is a common and easily avoidable mistake. The terms "cognitive aptitude test for hiring" and "logical thinking assessment" are sometimes used interchangeably with logical reasoning tests, but the five formats below measure meaningfully different things. Match the format to the cognitive demands of the role.
Deductive reasoning tests
Roles in compliance, QA, and legal analysis require following defined rules precisely, and deductive reasoning tests are the most direct measure of that skill. Candidates are given a set of premises and must identify which conclusion necessarily follows from them. No inference or guesswork is involved, only strict application of stated conditions. A candidate who consistently imports outside assumptions into a deductive problem will do the same thing when reading a technical specification.
Best suited for: quality assurance, compliance, legal analysis, policy enforcement.
Inductive reasoning tests
Data professionals and product managers spend most of their day doing exactly what inductive tests measure: pulling patterns from observations and deciding what those patterns imply. Candidates receive a number sequence, shape series, or data set and must identify the underlying rule to predict what comes next. The skill being assessed is identical to what an analyst does when building a predictive model.
Best suited for: data analysis, research, business intelligence, product management, strategic roles.
Abstract reasoning tests
Abstract reasoning tests use non-verbal shape and pattern matrices, which makes them the most culture-fair format available. Because the test contains no language, proficiency in English and educational background do not affect scores. A candidate who struggled with a second language in university can demonstrate exactly the same fluid intelligence as a native speaker. That matters for global pipelines and for organizations serious about reducing structural bias.
Best suited for: international or diverse hiring pipelines, roles where learning speed matters more than existing knowledge.
Diagrammatic reasoning tests
Debugging a system, tracing logic through a workflow, reading an architecture diagram: all of these are diagrammatic reasoning in practice. These tests present candidates with a flowchart or process map, give them an input value, and ask them to trace it through conditional steps to find the output. For technical hiring specifically, this is arguably the most directly role-relevant cognitive format available.
Best suited for: software engineering, systems design, DevOps, technical program management.
Critical thinking tests
Managing a team or advising a client means spending a significant portion of the day evaluating other people's arguments and deciding which ones are actually sound. Critical thinking tests present a short argument and ask candidates to identify its underlying assumptions or weaknesses. Unlike deductive tests, there is no single correct logical answer; the candidate must judge quality rather than just apply a rule.
Best suited for: management, consulting, product strategy, editorial roles, and leadership positions.
Sample logical reasoning questions (with answers)
The following five original questions span each test type. Each includes the question, answer options, the correct answer, and a brief explanation of the reasoning process.
Deductive reasoning example
Question: All software engineers on Project Delta are required to attend the weekly architecture review. Priya is attending the weekly architecture review.
Which of the following conclusions can be definitively drawn?
A) Priya is a software engineer on Project Delta. B) Priya may or may not be a software engineer on Project Delta. C) Priya is not a software engineer on Project Delta. D) Only software engineers attend the weekly architecture review.
Correct Answer: B
Explanation: The premise states that all Project Delta engineers must attend. It does not state that only Project Delta engineers may attend. Priya's presence is consistent with membership but does not prove it. Option A overstates what the premises allow. In deductive reasoning, the conclusion must follow necessarily, not just plausibly.
Inductive reasoning example
Question: What is the next number in the following sequence?
3, 6, 12, 24, 48, ?
A) 72 B) 84 C) 96 D) 64
Correct Answer: C
Explanation: Each number is twice the preceding one (3 x 2 = 6, 6 x 2 = 12, and so on). Applying the same rule: 48 x 2 = 96. The task is identifying the multiplication pattern from the observations, not performing a calculation you were explicitly told to run.
Abstract reasoning example
Question (described textually -- in a live test this would appear as a visual matrix):
A 3x3 matrix contains shapes. Top row: a small circle, a medium circle, a large circle. Middle row: a small square, a medium square, a large square. Bottom row: a small triangle, a medium triangle, and one missing shape (position 3,3).
Which shape correctly fills the missing position?
A) A small triangle B) A large triangle C) A large circle D) A medium square
Correct Answer: B
Explanation: Each row progresses from small to medium to large. The bottom row is triangles, so the final position requires a large triangle. The test checks whether a candidate can identify a consistent rule running across multiple dimensions simultaneously.
Diagrammatic reasoning example
Question: An input value of 8 passes through the following process:
Step 1: If the value is greater than 5, double it. If not, add 10. Step 2: If the result is even, subtract 6. If the result is odd, add 2. Step 3: If the result is greater than 8, divide by 2. If not, multiply by 3.
What is the final output?
A) 4 B) 5 C) 8 D) 10
Correct Answer: B
Explanation: Step 1: 8 > 5, so 8 x 2 = 16. Step 2: 16 is even, so 16 - 6 = 10. Step 3: 10 > 8, so 10 / 2 = 5. The correct output is 5. Diagrammatic questions test the ability to track a value through a conditional logic chain without losing the current state, the same mental move a developer makes when stepping through a nested conditional while debugging.
Critical thinking example
Question: "Because our last three product launches that included a public beta phase outperformed their revenue targets, we should include a public beta phase in all future product launches."
Which of the following is an assumption that underlies this argument?
A) The company has sufficient resources to run a public beta for every launch. B) The public beta phase was the primary reason the three launches exceeded their revenue targets. C) Future products will be similar in nature to the three previous launches. D) Both B and C
Correct Answer: D
Explanation: The argument assumes the beta phase caused the outperformance, not market timing, pricing, or product quality (Assumption B). It also assumes future products will respond to a beta phase the way past products did (Assumption C). Both assumptions need to hold for the conclusion to stand. Identifying that kind of compounded logical dependency is the core skill this question type measures.
How logical reasoning tests fit into the hiring funnel
A reasoning test dropped into a hiring process without a plan adds friction without adding accuracy. Where you place it determines how much value you actually get.
Screening stage (pre-interview)
The top of the funnel is where reasoning tests do their most efficient work, filtering a large applicant pool before any recruiter time is invested. For technical roles, pairing a logical reasoning assessment with a coding challenge in a single session can reduce the coordination work of running two separate screening rounds. HackerEarth's technical assessment platform supports this configuration, combining deductive or inductive reasoning questions with language-specific coding problems in one timed, remotely proctored session.
Interview stage (supplemental signal)
Some teams use shorter reasoning exercises during live interviews to observe how a candidate thinks out loud, which reveals more than a correct answer alone. Live technical interview tools like FaceCode integrate structured problem-solving directly into the interview session, pairing reasoning observation with real-time coding evaluation.
Final evaluation (composite scoring)
No single assessment method is accurate enough to carry a hiring decision on its own. At the final stage, reasoning scores should sit alongside structured interview ratings, technical assessment results, and relevant work samples. This composite approach also makes decisions easier to defend, since each component ties back to documented, job-relevant requirements.
How to implement logical reasoning tests in your hiring process
Implementation is where most assessment programs either deliver value or quietly fail. The following six steps keep the process both defensible and effective.
Step 1 - Define the cognitive requirements of the role
Start with a job analysis, not a test catalogue. Identify which reasoning skills the role actually requires: deductive for QA and compliance, inductive for data science and analytics, diagrammatic for engineering and systems design, critical thinking for management and strategy. Documenting this mapping ensures the assessment measures something genuinely relevant, and it creates a defensible record that links test content to job requirements if a hiring decision is ever challenged.
Step 2 - Select the right test format
Match test type to the cognitive demands from Step 1. For most technical roles, combining inductive, diagrammatic, and deductive formats provides the most complete coverage. Keep test length proportional to seniority -- 20 minutes is reasonable for a mid-level screening, and 45 minutes for an entry-level role will drive drop-off. A meaningful share of candidates will attempt the logical reasoning test online on a phone or tablet. Platform compatibility across devices is not optional.
Step 3 - Choose a validated logical reasoning test platform
The platform matters as much as the questions, because an assessment is only as defensible as the psychometric validation behind it. Look for documented reliability data, built-in proctoring, ATS integration, and the ability to run cognitive and technical questions in a single session. The right vendor will publish validation evidence, support accommodations, and integrate cleanly with your existing ATS.
Step 4 - Set benchmarks and scoring criteria
A raw score without context is nearly meaningless. Use normative benchmarking against a reference population, internal benchmarking calibrated to your own high performers, or percentile bands that map score ranges to hiring decisions. Avoid picking a pass mark at a round number without data to back it up, because a cutoff that looks clean often turns out to be arbitrary.
Step 5 - Communicate clearly with candidates
Completion rates rise when candidates know what to expect before the test window opens. Telling candidates the format, total time allowed, what the assessment is measuring, and when the deadline falls is not just courtesy -- it directly affects who completes the assessment and therefore the quality of the pool you hear back from. HackerEarth's guidance on improving the candidate experience covers how to communicate assessment expectations at each funnel stage.
Step 6 - Analyze logical reasoning test results and iterate
An assessment program that never gets reviewed drifts toward irrelevance over time, like any process that stops being checked against outcomes. After each hiring cycle, review three things: adverse impact across demographic groups, candidate completion rates, and whether top-quartile scorers actually perform better on the job. Adjusting benchmarks and question difficulty based on that data is what separates a mature program from one that just adds a hurdle. For a broader framework, HackerEarth's overview of skills-based hiring covers how reasoning data fits alongside other performance signals.
Best practices for fair and effective logical reasoning assessments
Most assessment programs that get challenged or abandoned could have avoided both outcomes with a few operational decisions made early.
- Use professionally developed, validated tests. Unverified question banks carry no reliability guarantees and create legal exposure.
- Document the job-relevance link before deployment. Recording exactly how the test content maps to your job analysis is the primary line of defense if a hiring decision is ever scrutinized.
- Monitor for adverse impact after every cycle. Under the EEOC Uniform Guidelines on Employee Selection Procedures and disparate impact doctrine under Title VII, employers are expected to track whether selection procedures produce disproportionate pass/fail rates across protected groups. A common benchmark is the "four-fifths rule": if the selection rate for any group is less than 80% of the rate for the highest-scoring group, that is treated as evidence of adverse impact and triggers a closer look.
- Never use reasoning scores in isolation. Pair them with a structured interview, technical evaluation, and a work sample.
- Keep screening-stage test duration to 15 to 30 minutes. Longer assessments at the top of the funnel filter out high-demand candidates who have more options and will not wait.
- Provide accommodations for candidates with disabilities. Extended time, screen reader compatibility, and alternative formats are standard requests and legally required in most jurisdictions.
- Use remote proctoring for online assessments to protect test integrity rather than to survey. Proctoring that flags genuine anomalies quietly serves the goal; proctoring that treats every candidate as a suspect undermines the experience you are trying to create.
Bottom line: defensibility comes from documentation, not just from picking a good test.
Logical reasoning tests for technical hiring: a special case
Technical hiring benefits from logical reasoning tests more than most domains, not because engineers need to be generically smart, but because the cognitive tasks these tests measure are literally what engineers do all day.
Debugging is deductive reasoning: given a known system state and a failure condition, identify the rule violation that produced the error. System design is abstract and diagrammatic reasoning: reason about dependencies and constraints across interconnected components. Data engineering is inductive: extract generalizable rules from incomplete or noisy datasets. A coding assessment tells you what a candidate can build today with the patterns they already know. A logical reasoning assessment tells you how they will approach a problem they have never seen before. Both pieces of information matter, and neither substitutes for the other.
For technical hiring teams, the operational question is how to surface both signals without doubling the number of screening rounds. HackerEarth's platform lets hiring teams build multi-skill assessments that include logical reasoning modules alongside coding interview questions, language-specific challenges, system design prompts, and technical MCQs in a single timed session.
What strong candidates already know (and what that means for your test design)
The candidates most likely to pass a logical reasoning test have prepared specifically for the format. Understanding what those candidates do — and do not — bring to test day helps hiring teams design assessments that measure thinking ability rather than test familiarity.
- Strong candidates find out the test format before test day. Deductive, inductive, abstract, and diagrammatic questions each call for a different approach. If your communications do not specify format up front, you are advantaging candidates who already know what to look for.
- They practice under timed conditions. Time pressure feels different from untimed practice. If your test design assumes candidates have never worked against a clock, scores will be confounded with test-taking experience rather than reasoning ability.
- They review wrong answers for underlying logic, not just the correct letter. Test design should reward pattern recognition, not memorization.
- In deductive questions, they stick strictly to stated premises rather than importing real-world assumptions. Hiring teams should write items that explicitly punish assumption-import, which is a job-relevant failure mode.
- They skip and return rather than getting stuck. Test design that allows skip-and-return reflects how strong reasoners actually work; tests that lock candidates into linear progression often measure persistence under frustration rather than logical ability.
- They treat the test as a measure of thinking ability, not stored knowledge. Communicating this clearly to candidates levels the playing field and improves the signal-to-noise ratio of your scores.
The takeaway for employers: clear pre-test communication, fair time limits, and item design that targets the right failure modes do more for assessment quality than raising the difficulty does.
Common mistakes employers make with logical reasoning tests
Most of these mistakes are avoidable once you know to look for them.
- Using unvalidated or generic tests. Free question banks and internet puzzles offer no psychometric guarantees and create legal liability.
- Over-relying on reasoning scores. A high score indicates cognitive potential, not proven competence. Always interpret alongside skills and experience data.
- Setting arbitrary cutoff scores. A pass mark chosen without normative data is as likely to exclude strong candidates as weak ones.
- Failing to explain the test to candidates. Candidates who do not understand what is being measured and why are more likely to drop out, which skews the applicant pool before a single score is reviewed.
- Ignoring adverse impact data. A test that performs cleanly on one candidate cohort may produce skewed outcomes on another. Reviewing this after each cycle is not optional.
- Deploying assessments that are too long at the screening stage. Anything over 35 to 40 minutes at the top of funnel significantly increases drop-off, and the candidates with the most alternatives are the most likely to leave.
Conclusion
Logical reasoning tests are among the best-validated hiring tools available, and the research on their predictive accuracy is not close. The challenge is not whether to use them; it is whether to use them correctly.
The essentials: match the test type to the cognitive demands of the role, use a platform with documented psychometric validation, combine reasoning scores with technical assessments and structured interviews, and communicate clearly with candidates throughout. For technical teams, running reasoning and coding evaluations in a single session gives the most complete picture of a candidate while reducing the coordination work of two separate screening rounds.
Next steps: see it in action
If you are ready to build a more defensible hiring process, explore HackerEarth's technical assessment platform to see how logical reasoning and skills-based assessments can work together in your next hiring cycle.
Frequently asked questions
What is a logical reasoning test?
A logical reasoning test is a standardized assessment of pattern recognition, deductive inference, and argument evaluation that deliberately strips out domain knowledge — which is also its main scope limit. Because it does not measure what a candidate already knows about your industry, it should never be used to assess role-specific competence, only the cognitive horsepower a candidate will bring to learning that competence.
How many questions are on a logical reasoning test?
Most pre-employment logical reasoning tests contain 15 to 30 questions with a time limit of 15 to 35 minutes, depending on the provider and the role. In practice, shorter tests at the screening stage tend to produce better completion rates without sacrificing meaningful signal.
Are logical reasoning tests hard?
Logical reasoning tests are moderately challenging by design, but they measure thinking ability rather than specialized knowledge, so there is nothing to memorize. The candidates who find them hardest are usually the ones who spend too much time second-guessing themselves rather than working methodically.
How do you pass a logical reasoning test?
Understand the format before test day, manage your time deliberately, read premises carefully, eliminate clearly wrong options first, and practice under timed conditions. Staying methodical matters considerably more than raw speed.
Do logical reasoning tests predict job performance?
Yes, but with important moderators. Predictive validity is strongest for high-complexity roles (engineering, management, analytics) where novel problem-solving is constant, and noticeably weaker for highly routine roles where job knowledge and consistency matter more than fluid reasoning. Validity also degrades when reasoning scores are used as a standalone gate rather than combined with structured interviews and work samples