How to evaluate software engineers before the interview: a technical assessment tools guide
The average time to hire a software engineer in the U.S. is 42 days, and teams now conduct an average of 20 interviews per hire, 42% more than in 2021, according to Gem's 2025 recruiting benchmarks report. A significant portion of that time is spent on live interviews with candidates who were never truly qualified in the first place.
Technical assessment tools for software engineers — platforms that evaluate coding ability, problem-solving, and applied technical skill before a live interview — can shift this dynamic. Used correctly, they evaluate developers before the interview stage, filter out mismatched candidates before a single engineer's calendar gets blocked, create a standardized and defensible scoring record, and can improve the interview-to-offer ratio enough to measurably shorten the hiring cycle. Pre-employment technical tests and structured online coding assessments may reduce time-to-hire, with LinkedIn's Future of Recruiting research and SHRM's talent acquisition reports both pointing to meaningful efficiency gains from structured pre-screening. This guide walks through an eight-step framework for evaluating software engineers before the interview, with specific guidance for recruiters and hiring managers at each step.
Skipping pre-screening is an expensive decision, and the numbers make that concrete. The U.S. Department of Labor estimates a bad hire costs at least 30% of that employee's first-year wages. SHRM places the cost of replacing an employee at between 50% and 200% of their annual salary, depending on seniority. For a $120,000 senior engineering role, a single bad hire can cost between $60,000 and $240,000 once you factor in lost productivity, re-hiring, and team disruption.
Structured pre-interview technical evaluation addresses this in three ways. First, it can reduce time-to-hire by replacing subjective resume screens with objective skill signals that help hiring managers move faster with confidence. Second, it raises the interview-to-offer ratio: when only genuinely qualified candidates reach the live interview stage, engineering teams spend less time on conversations that go nowhere. Third, technical candidate screening produces a better candidate experience than a six-round process with no clear structure.
The data on skills-based hiring reinforces this. According to TestGorilla's 2024 State of Skills-Based Hiring report, most employers agree skills-based hiring is more predictive of on-the-job success than resumes alone, and a large share of employers using it report a measurable reduction in mis-hires. The same report indicates that skills-assessed hires can outperform resume-screened hires on first-year job performance metrics.
The tools that make this practical are covered in the steps below. For context on how to build the earlier funnel that feeds into assessment, see this guide to building a candidate pipeline that cuts your cost and time to hire.

Step 1: Define the technical skills you need to evaluate
The most common reason a software engineer assessment fails to predict job performance is that it tests the wrong things. A useful technical skills evaluation starts not with a question library but with the job itself.
Map skills to role requirements
Work backward from what the engineer will actually do in their first 90 days. Distinguish between language-specific skills (writing Python data pipelines, writing TypeScript components) and broader competencies (system design, debugging, API integration, code review). A backend role that requires building REST APIs in Node.js needs a different assessment than one that requires optimizing SQL queries in a legacy codebase.
The table below provides a starting framework:
| Role | Core Skill | Assessment Type |
|---|---|---|
| Backend Engineer | API design, data structures, SQL | Coding challenge + MCQ |
| Frontend Engineer | JavaScript/TypeScript, DOM manipulation, UI logic | Code challenge + project task |
| Data Engineer | Python, SQL, pipeline design | Coding challenge |
| DevOps Engineer | Scripting, CI/CD concepts, infrastructure | MCQ + scenario task |
| QA Automation Engineer | Test framework design, debugging, edge cases | Coding challenge + project task |
| Full-Stack Developer | Frontend + backend integration, architecture | Project-based task |
Prioritize must-have vs. nice-to-have skills
Over-testing is a real risk. Assessments that try to cover eight skill areas produce two outcomes: senior engineers abandon the process, and the results are harder to interpret because the scoring signal gets noisy.
Limit pre-interview assessments to three to five must-have skills: the ones where a gap would make the candidate unable to perform the role regardless of everything else. Nice-to-have skills (frameworks the team uses but could teach, or secondary language knowledge) are better evaluated in the live interview, where they can be explored conversationally. Keeping the assessment tight respects the candidate's time and keeps your scoring focused on what actually predicts job fit.
Step 2: Choose the right type of technical assessment
Not all developer assessment tools are designed for the same purpose, and mixing up assessment types is one of the more common and costly process mistakes. Here is how the main formats compare:
Coding challenges and algorithm tests
Coding challenges test problem-solving speed, data structure fluency, and language command. They are well-suited for entry-level and junior hiring, and for roles where algorithmic thinking is genuinely central to the work. The limitation is well-documented: algorithm-focused competitive programming tests often favor candidates who have practiced that specific style rather than those who write excellent production code. Senior engineers (the people who could actually do the job) frequently underperform on these tests relative to their actual capability.
Use algorithm tests as one signal, not the only one.
Project-based and take-home assessments
Take-home projects give candidates space to demonstrate how they actually write code: structure, naming, error handling, test coverage, documentation. For mid to senior roles, this format produces the richest signal and is a meaningful step up from pre-hire coding tests that rely entirely on algorithmic correctness. The tradeoff is time: candidates who are currently employed and fielding multiple offers often decline assessments that require more than two to four hours. Poorly designed take-homes with vague instructions compound this problem. Keep scope tight, share the evaluation criteria upfront, and communicate clearly what "done" looks like.
MCQ-based knowledge tests
Multiple choice tests are useful for screening foundational knowledge at scale and for quickly filtering out candidates who lack the minimum baseline for a role. They are fast to complete (typically 20 to 40 minutes) and straightforward to score. What they cannot assess is applied skill: a candidate who knows the definition of a race condition is not necessarily someone who can find one in a codebase. Use MCQs as a first-pass filter, particularly in high-volume hiring, rather than as a primary evaluation tool.
AI-powered and adaptive assessments
Newer technical assessment tools for software engineers adjust difficulty in real time based on how a candidate is performing. The underlying AI is trained on patterns of candidate responses across difficulty levels and uses item-response models to calibrate which question to serve next. Its limit is that it depends on the quality and breadth of the underlying question bank: an adaptive engine on a narrow library will not produce meaningfully better signal than a fixed test. A candidate who answers the first three questions correctly gets progressively harder questions; one who struggles gets redirected to calibrate the baseline. This produces more accurate skill-level profiling than a fixed-difficulty test and reduces the likelihood that a genuinely strong candidate fails on a single hard question. HackerEarth's adaptive assessments use this approach to give hiring teams a more nuanced picture of where a candidate sits within a skill range rather than a simple pass/fail.
Assessment type comparison
| Assessment Type | Best For | Time Required | Insight Level | Limitations |
|---|---|---|---|---|
| Coding Challenge | Junior/mid-level; algorithmic roles | 60–90 min | Medium | Can favor practice over real-world skill |
| Take-Home Project | Mid/senior roles; code quality evaluation | 2–4 hours | High | Higher drop-off rate; time-intensive to review |
| MCQ Knowledge Test | High-volume screening; baseline checks | 20–40 min | Low–medium | Tests recall, not applied skill |
| AI-Powered Adaptive (trained on response patterns; limited by question-bank breadth) | All levels; nuanced skill profiling | 45–75 min | High | Requires platform support |
Step 3: Select a technical assessment tool that fits your workflow
The right technical assessment tool for software engineers is one that integrates with your existing hiring workflow, matches the roles you actually hire for, and produces scoring you can defend. Treat the selection as a procurement decision with the same rigor as any other tooling choice. The market for programming assessment tools ranges from lightweight quiz platforms to full-stack technical hiring suites. A platform with a large question library but no ATS integration will create manual work that slows the process you were trying to speed up.
Key features to evaluate
When comparing technical screening tools, weigh these capabilities against the trade-offs each one carries:
- Question library breadth vs. relevance: A larger library is not always better. A smaller, well-curated library aligned to your stack may outperform a sprawling one with thin coverage of your actual languages.
- Language and framework support: Candidates code better in their preferred environment, but supporting every language adds maintenance overhead for the vendor and can dilute question quality.
- ATS integration: Native integrations reduce manual data entry, but a deep integration with one ATS can mean shallow support for others. Confirm support for your specific system.
- Automated scoring vs. human review: Automated scoring is consistent and fast but can miss nuance in code quality. The best platforms combine both.
- Anti-cheat and proctoring: More aggressive proctoring improves integrity but degrades candidate experience. Calibrate to assessment stakes.
- Customization: Custom questions improve role fit but require internal time to author and maintain.
- Reporting and analytics: Side-by-side comparison helps hiring decisions, but only if the underlying scoring is consistent.
- Candidate experience: A clean interface and clear instructions reduce drop-off, particularly for senior candidates.
Integration with your existing tech stack
A technical assessment tool that lives outside your ATS creates friction at every stage: sending invitations manually, importing results by hand, and reconciling candidate records across systems. Prioritize platforms that offer native integrations with the tools your team already uses. Common integrations to verify include Greenhouse, Lever, Workday, SAP SuccessFactors, Jobvite, and Bamboo HR.
Where HackerEarth fits
HackerEarth's technical assessment platform supports 40+ programming languages and a question library spanning 1,000+ skills, with automated candidate reports that let hiring managers compare performance side by side without manual scoring. For a recruiter running parallel hiring for a backend engineer, a data engineer, and a DevOps role in the same quarter, the practical value is that a single platform handles role-specific assessment design, scoring, and ATS handoff without bouncing between vendors. The platform also includes HackerEarth FaceCode for live coding interviews and OnScreen, an AI-led interviewer for first-round screening conversations.
Step 4: Design assessments that reflect real work
A platform with a strong question library still produces poor results if the assessment design is wrong. The most common design failure is sending candidates an assessment that has nothing to do with the actual job.
Replace trick questions with role-relevant scenarios
Recruiter and engineering communities are full of candidates describing assessments they abandoned because the questions tested abstract algorithms they had not touched since school and would never use in the role. That frustration is a signal worth taking seriously: when senior engineers with options encounter an irrelevant assessment, they drop out. The candidates who push through are often the ones with fewer competing offers.
Map each assessment question to a task the engineer would actually perform in their first 90 days. If the role involves optimizing database queries, test that. If it involves debugging a failing API endpoint, test that. The candidate experience should feel like a preview of the work, not an unnecessary obstacle.
Set realistic time limits
As a benchmark: coding challenges should sit in the 60 to 90 minute range. Take-home projects should be capped at two to four hours, with scope defined tightly enough that a strong candidate can finish comfortably within that window. Assessments longer than these thresholds see significantly higher drop-off rates, particularly among candidates who have multiple processes running in parallel.
For guidance on improving the candidate experience throughout the evaluation process, including how to reduce friction at the assessment stage, see HackerEarth's candidate experience resources.
Include clear instructions and context
Candidates perform better, and produce more useful signals, when they understand what is being evaluated. Provide the rubric criteria upfront: tell candidates whether you are weighting correctness, code quality, or test coverage. Share the evaluation framework. This is not giving away the answers; it is giving candidates the context they need to show their best work rather than guessing at what you care about. Rubric transparency also reduces the likelihood that a strong candidate fails on a technicality and a weaker one passes by guessing correctly.
Step 5: Protect assessment integrity with proctoring
Assessment integrity in remote hiring depends on layered safeguards: browser lockdown, webcam monitoring, plagiarism detection, and clear candidate communication. The need is real. According to reports, a significant share of candidates have used AI tools to complete assessments or applications, and the Identity Theft Resource Center has documented sharp increases in resume and application fraud between 2023 and 2024. An assessment process with no integrity measures produces results you cannot trust.
Effective remote proctoring for online assessments typically combines several layers. Browser lockdown prevents tab switching and unauthorized resource access. Webcam monitoring uses computer vision to flag suspicious behavior. Plagiarism detection compares submissions against known solutions. IP tracking surfaces unusual login patterns or proxy use.
Candidate privacy is a real consideration and worth addressing directly. Most candidates understand and accept reasonable proctoring when it is communicated clearly before the assessment begins. The problem is surprise: candidates who discover they are being monitored without warning react negatively, and the employer brand damage from that reaction can spread quickly on platforms like Glassdoor. Communicate your proctoring approach in the assessment invitation, explain why it exists, and keep the monitoring proportionate to the assessment stakes. A first-pass MCQ screen does not need the same level of oversight as a final-stage coding project.
Step 6: Score and rank candidates objectively
A strong assessment process can still produce biased or inconsistent outcomes if the scoring is done inconsistently. Objective scoring is not just a fairness issue — it is a signal quality issue. Inconsistent scoring produces a shortlist that reflects reviewer preference rather than candidate capability.
Use standardized rubrics
Every candidate should be evaluated against the same criteria, weighted the same way. A sample rubric for a coding challenge:
| Criterion | Weight |
|---|---|
| Correctness (does the code produce the right output?) | 40% |
| Code Quality (readability, naming, structure) | 25% |
| Efficiency (time and space complexity) | 20% |
| Edge Case Handling (boundary inputs, error states) | 15% |
Define what "meets expectations" looks like for each criterion before scoring begins. This prevents reviewers from adjusting their standards upward or downward based on the overall impression a candidate makes.
Use automated scoring
Automated test-case evaluation removes much of the subjectivity involved in manually reviewing code output. Automated technical assessment platforms generate performance reports that compare candidates side by side against the same benchmark, giving hiring managers a ranking grounded in objective criteria rather than reviewer impressions. Automated scoring also dramatically reduces the time engineers spend reviewing submissions, which matters when you have 50 assessment results waiting.
Reduce unconscious bias
Removing candidate identifiers from the scoring view is one of the simplest and most evidence-backed changes you can make to improve both fairness and hiring outcomes. Research aggregated by industry sources suggests that removing names and photos from applications can meaningfully increase interview rates for underrepresented candidates, with the underlying findings often traced back to controlled studies in academic labor economics. In the technical hiring context, this means scoring candidates based on their code, not their name, university, or previous employer. Many technical assessment platforms support anonymized submission review as a default setting.
Step 7: Communicate results and move top candidates forward
Clear, timely communication after the assessment is what separates hiring processes that protect employer brand from those that quietly erode it. This step is where most hiring processes break down in a way that costs real money.
Provide timely, constructive feedback
Talent Board research has consistently found that candidates who receive feedback (even a rejection) rate the employer more favorably than those who receive silence. With Greenhouse data indicating widespread candidate ghosting after interviews in 2024, any communication at all puts you ahead of most competitors. For candidates who reach the assessment stage and do not progress, a brief note with at least a general indication of where they did not meet the bar is worth the investment. It protects your employer brand and keeps the door open for future applications from candidates who improve.
Set clear expectations for the interview stage
Tell shortlisted candidates what the live interview will cover before they arrive. Specify whether the interview will include a live coding exercise, a system design discussion, or purely behavioral questions. This serves two purposes: it respects the candidate's time by preventing them from preparing for the wrong thing, and it signals that your process is organized and intentional, which is itself a positive signal about the company.
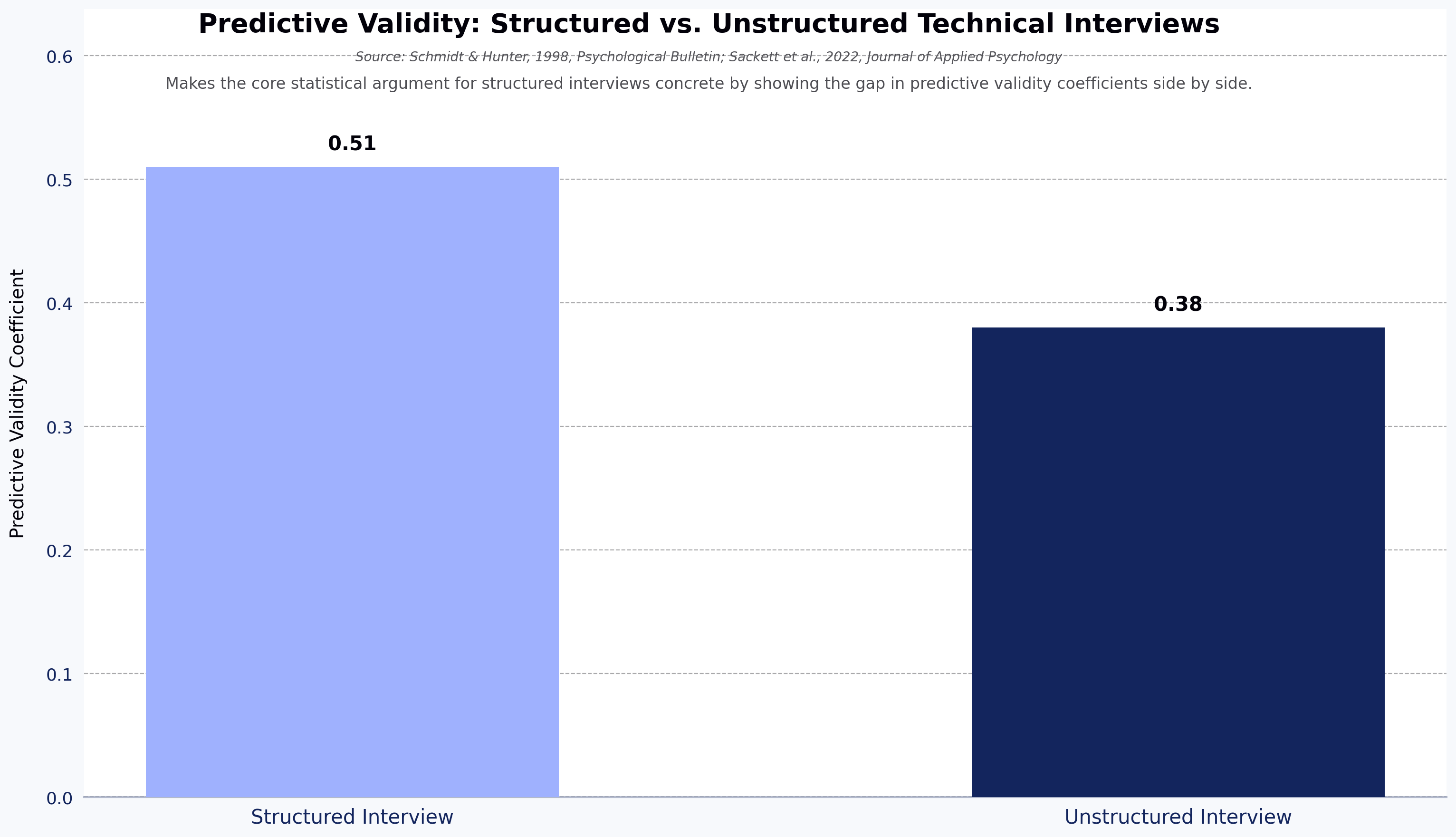
For a breakdown of platforms and formats for the live interview stage, see HackerEarth's guide to conducting structured technical interviews.
Step 8: Measure and refine your assessment process
An assessment process that never gets reviewed stops being useful. The questions that filtered well last year may not be discriminating effectively this year, especially as AI tools make it easier for candidates to generate plausible-looking answers to standard coding prompts.
Track key metrics
Build a regular review around these signals:
- Assessment completion rate: What percentage of candidates invited to the assessment actually finish it? A completion rate below 60-70% suggests the assessment is too long, too opaque, or is reaching the wrong candidate profiles.
- Candidate drop-off rate: At which point in the assessment do candidates abandon? This identifies specific friction points.
- Score-to-interview pass rate correlation: Are the candidates who score highest on the assessment actually passing the live interview at higher rates? If not, the assessment is not measuring what matters.
- Time-to-hire: Is the pre-screening step actually compressing the total hiring cycle?
- Quality of hire: Are engineers who performed well on the assessment also performing well at their 90-day review?
Iterate on question content
Retire questions that have leaked into the internet. Track which questions show suspiciously high pass rates over time as a signal that answers are being shared. A/B test assessment lengths: run a shorter version with your must-have skills only and compare outcomes to a longer version. Solicit candidate feedback post-assessment through a brief survey. The candidates who completed your process have direct experience with it; their feedback is more actionable than most internal assumptions about what a good assessment experience looks like.
Common mistakes to avoid
Even teams with the right tools and intentions make predictable process errors. Five recur most often:
Testing skills that are irrelevant to the role. An algorithm puzzle disconnected from day-to-day work measures interview preparation rather than job readiness. The cost shows up as qualified senior candidates dropping out mid-assessment when they recognize the mismatch.
Using the same assessment for all engineering levels. A test designed for junior engineers will not reveal anything useful about a senior candidate's architecture thinking or system design capability. Level-appropriate assessments require different question types, time expectations, and evaluation criteria — for example, a junior MCQ screen on data structures versus a senior take-home on designing a rate-limited API.
Ignoring candidate experience. Confusing instructions, slow-loading test environments, or missing context about evaluation criteria all signal something about your engineering culture. Candidates draw conclusions from the process before they ever meet the team, and senior candidates are the most willing to opt out.
Skipping proctoring for remote roles. A well-publicized case of assessment fraud in a high-stakes hire can undermine the credibility of your entire screening process. Basic integrity measures — browser lockdown, plagiarism detection, clear candidate disclosure — are straightforward to implement and proportionate to deploy.
Treating assessment scores as the only hiring signal. Assessment scores predict technical capability. They do not predict communication, collaboration, ability to navigate ambiguity, or cultural alignment with a specific team. The strongest hiring processes use assessment results to inform interviews, not replace them.
Frequently asked questions
What are technical assessment tools?
Technical assessment tools are software platforms that evaluate a candidate's programming skills, problem-solving ability, and technical knowledge through coding challenges, quizzes, or project-based tasks. They automate scoring and produce standardized records that hiring teams can use to compare candidates against a consistent benchmark.
How long should a pre-interview technical assessment take?
For coding challenges, 60 to 90 minutes is the standard range; take-home projects should be capped at two to four hours. Beyond those thresholds, drop-off rates increase substantially, and senior engineers with competing offers are the first to leave.
Can technical assessments replace interviews entirely?
No. Assessments screen for technical competency; interviews evaluate communication, collaboration, cultural alignment, and the kind of reasoning that does not show up in code output. The strongest hiring processes use assessments to filter candidates before the interview, not as a substitute for one.
How do you prevent cheating on online technical assessments?
Use a combination of browser lockdown, webcam proctoring, plagiarism detection, and IP monitoring, and communicate all of it to candidates before they begin. HackerEarth's enterprise-grade proctoring monitors for irregularities during the assessment, balancing integrity with candidate trans