




How to Conduct a Technical Interview: 7-Step Guide
If you're a recruiter trying to figure out how to conduct a technical interview that produces comparable, defensible candidate data, the bottleneck is rarely the questions — it's the inconsistency between interviewers. Your engineering team just rejected three candidates in a row, and none of the interviewers can agree on why. One wanted stronger system design instincts. Another marked down a candidate for nerves during a whiteboard exercise. A third made an offer to someone the others found underwhelming. The evaluations were inconsistent because the technical interview process was inconsistent.
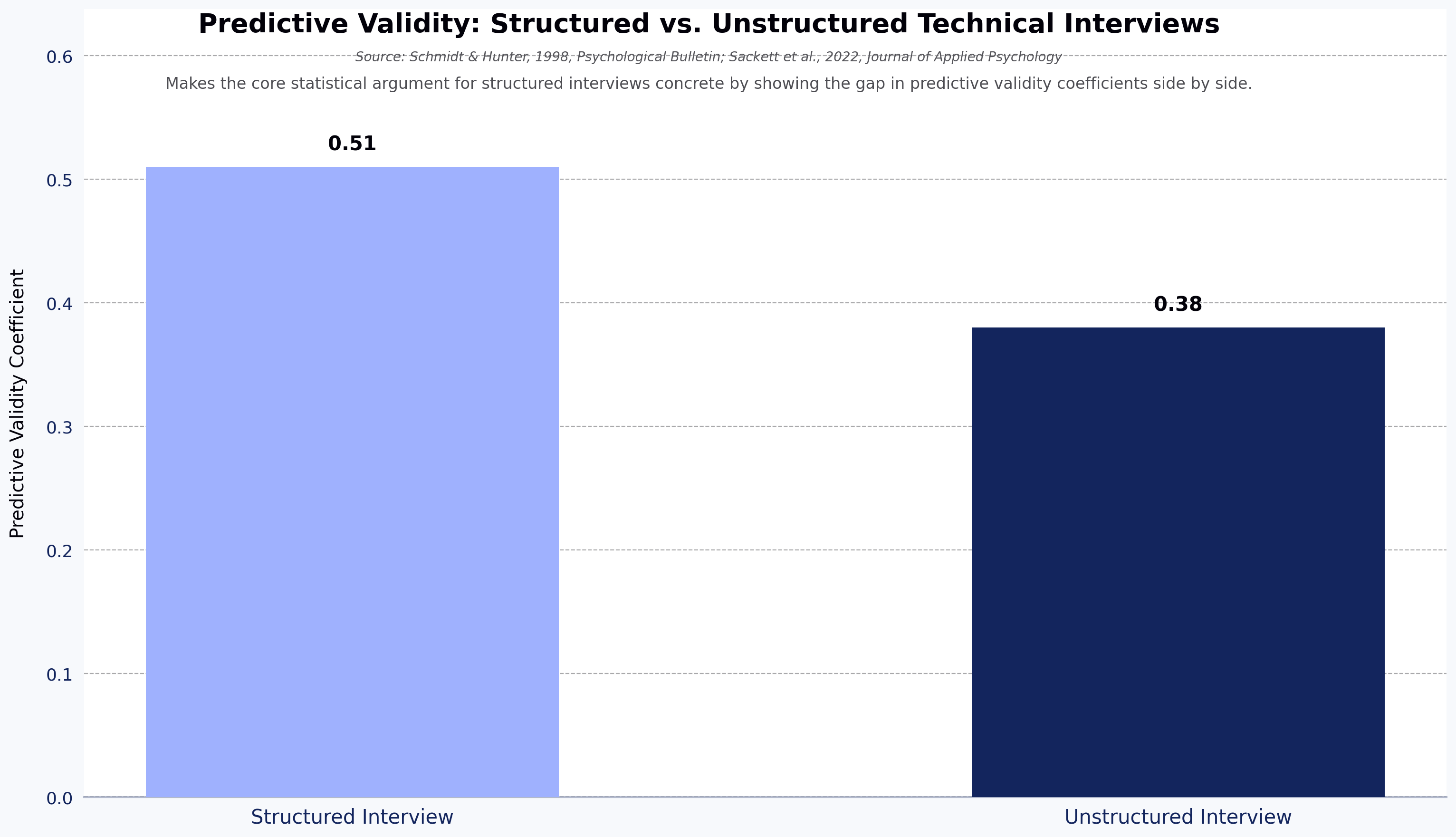
Research suggests structured technical interviews predict on-the-job performance at nearly twice the rate of unstructured ones: structured formats are reported at a predictive validity coefficient of around .51 compared to .38 for ad-hoc approaches (Schmidt & Hunter, 1998, Psychological Bulletin; the .51/.38 ordering has been revisited in more recent meta-analytic work, including Sackett et al., 2022, Journal of Applied Psychology). Yet most technical interview processes remain a patchwork of interviewer preferences, inherited question banks, and gut-feel scoring.
This guide gives recruiters a direct answer to how to conduct a technical interview: a seven-step framework for conducting technical interviews that generate comparable, defensible candidate data every time. It covers where AI interview agents — software that runs a structured first-round technical interview without a human interviewer, asking adaptive questions and scoring responses against a fixed rubric — fit into the technical hiring process and where they can measurably improve it. It is written primarily for recruiters and talent acquisition leads, with shared vocabulary for the hiring managers and engineering leads they partner with.
What Is a Technical Interview (and Why Your Process Needs a Rethink)?
A technical interview is a structured candidate evaluation that assesses engineering skills through role-relevant challenges, including live coding, system design problems, debugging exercises, pair programming, and technical phone screens. Unlike a general interview, its goal is to surface evidence of actual technical capability rather than self-reported experience.
The main formats generate different signal types. Live coding tests algorithmic thinking under pressure. System design evaluates architecture instincts at scale. Pair programming reveals how someone works alongside teammates. Take-home assignments show production-quality code without time pressure. Technical phone screens handle high-volume screening early in the pipeline.
The cost of getting the evaluation wrong is not abstract. A commonly cited industry estimate, frequently attributed to the U.S. Department of Labor, puts the cost of a bad hire at roughly 30% of the employee's first-year salary; the original source is disputed, so treat the figure as directional rather than precise. As an illustration: if a mid-level engineer earns around $140,000, that 30% rule-of-thumb would imply roughly $42,000 in recruiting, onboarding, and lost productivity before you start over. The cause is usually not that the wrong person got through; it is that the process never collected enough consistent signal to tell candidates apart.
Step 1 — Define the Role Requirements and Technical Competencies for the Interview
Building interview questions before defining what you are evaluating is the technical hiring equivalent of writing test cases for a feature that has not been specified. Partner with the engineering lead to document must-have versus nice-to-have skills before writing a single question. The output is a competency matrix that anchors every evaluation decision from screening through the final panel.
How to Build a Technical Competency Matrix
Work through three steps: list the role's core daily tasks, map each task to a measurable skill, and assign a minimum proficiency level on a beginner, intermediate, or expert scale.
Sample matrix for a mid-level backend engineer:
| Core Task | Required Skill | Minimum Level | Interview Signal |
|---|---|---|---|
| Design RESTful APIs | API design patterns | Intermediate | System design round |
| Write production Python/Go | Language proficiency | Intermediate | Live coding round |
| Debug production incidents | Debugging and logging | Intermediate | Code review exercise |
| Review pull requests | Code quality standards | Intermediate | Pair programming |
| Work with databases | SQL and data modeling | Intermediate | Domain-specific questions |
| Understand system trade-offs | Distributed systems basics | Beginner | System design round |
If an interviewer cannot tie their evaluation to a row in this matrix, their feedback belongs in notes, not in the scoring rubric.
Step 2 — Choose a Structured Technical Interview Format
Not every format generates the same signal for every role. Choosing formats before the pipeline opens ensures every candidate gets the same evaluation, which is the precondition for fair comparison.
Matching Interview Formats to Role Type
- Live coding: best for algorithmic and data structure roles, junior to mid-level engineers, and positions requiring frequent problem decomposition
- System design: best for senior and staff engineers; evaluates architecture thinking, trade-off reasoning, and communication under ambiguity
- Pair programming: best for teams where collaboration style strongly predicts success; reveals how someone works with a partner under real conditions. For live whiteboarding or extended pair-programming with the hiring team, a dedicated live-coding interview tool such as HackerEarth's FaceCode gives both sides a shared editor and standardized rubric to work from.
- Take-home assignment: best when production-quality code matters more than in-the-moment speed; works well for senior and specialist roles
- Technical phone screen: best for high-volume first-round filtering; a short, scripted, repeatable format enables fair comparison at scale
A common pipeline combination is automated technical screening, followed by an AI interview agent for first-round evaluation, followed by a live human panel. Each stage adds a different data type: objective code scores, adaptive conversational signal, and interpersonal judgment.
Step 3 — Prepare Technical Interview Questions and Scoring Rubrics
The ability to conduct coding interviews effectively depends less on the questions you choose than on the system you build around them. When technical interview questions are prepared without a shared rubric, post-interview calibration becomes an argument about preferences rather than an analysis of evidence.
Types of Technical Interview Questions
Five categories map directly to the competency matrix from Step 1:
- Algorithmic and coding: problem decomposition, time and space complexity, implementation correctness
- System design: scalability, fault tolerance, component trade-offs, technology selection rationale
- Debugging and code review: identifying defects in provided code, explaining root causes, proposing fixes
- Domain-specific: cloud architecture, ML pipelines, database optimization, security considerations
- Behavioral-technical hybrids: past incidents, technical decisions under constraints, disagreements with technical approaches
Avoid trick questions. A question a candidate could never encounter on the job produces data about their interview preparation, not their engineering ability. For role-aligned question sets, see HackerEarth's library of coding assessment questions.
Building a Scoring Rubric That Removes Guesswork
A scoring rubric converts a conversation into data by anchoring every rating to observable evidence, so post-interview debate is about scores rather than competing impressions.
Sample rubric for a live coding round:
| Criterion | 1 (Does Not Meet) | 3 (Meets Expectations) | 5 (Exceeds) |
|---|---|---|---|
| Problem-solving approach | No clear method; jumps to code immediately | Clarifies requirements, outlines approach before coding | Asks probing questions, considers edge cases upfront |
| Code correctness | Solution does not pass core test cases | Solution handles core cases; minor gaps in edge cases | All test cases pass; candidate identifies potential issues |
| Code quality | Unreadable or unstructured code | Readable, functional, lacks optimization | Clean, efficient, with clear naming and structure |
| Communication | Silent throughout; cannot explain reasoning | Narrates approach but struggles with questions | Explains every decision; adapts well to follow-up questions |
| Speed and accuracy | Did not complete the task | Completed with time to spare; small errors | Efficient solution delivered early; error-free |
Each interviewer completes the rubric immediately after the interview, before any group discussion. This protects individual judgment from social pressure and makes calibration faster because everyone compares scores, not competing narratives.
Step 4 — Set Up the Interview Environment and Tools
A candidate who spends the first ten minutes troubleshooting a broken code editor is not demonstrating their engineering ability; they are demonstrating patience. Remove environment friction before the interview starts.
For in-person: confirm IDE or whiteboard setup, test the development environment with the actual question the day before, and ensure the candidate knows which language the company expects.
For remote technical interviews, the most common failure points are environmental: use a shared coding environment rather than a screen share, test video and audio at least 15 minutes before the session, and send any installation instructions 48 hours in advance. For live coding and system design rounds run by the hiring team, HackerEarth's FaceCode provides a shared editor, structured question flow, and rubric-aligned scoring inside one tool.
Step 5 — Use AI Interview Agents to Standardize the First-Round Technical Interview
AI interview agents are reshaping how teams run first-round technical screens because they remove the engineer's calendar from the critical path. These tools present candidates with a question set, adapt follow-up questions based on candidate responses in real time, evaluate code as it is written, and flag integrity anomalies, so every candidate gets an identical evaluation environment.
HackerEarth's AI interview tool for this stage is OnScreen — HackerEarth's AI interview tool that conducts structured technical interviews 24/7 using video-avatar interviewers and built-in identity verification. OnScreen pairs lifelike AI video-avatar interviewers with KYC-grade identity verification and enterprise-grade proctoring, then produces a structured evaluation report covering code correctness, approach quality, communication, and time usage. The AI here is doing three specific things: matching candidate answers to a fixed competency rubric, generating adaptive follow-ups from a curated question bank, and scoring code against test cases written by the hiring team. Its limits are equally specific — it does not assess team-fit, long-horizon design judgment, or anything outside the question set the hiring team configures.
As a directional guideline, AI-led first-round screens often run in the 30–45 minute range, though the right length depends on role seniority and question set rather than the tool.
See it in action: Book a demo of OnScreen to walk through how a structured first-round technical interview runs end to end.
Step 6 — Conduct the Interview With Consistency and Fairness
Consistency in a technical interview does not mean reading questions off a script; it means every candidate is evaluated on the same criteria so comparison is meaningful rather than a negotiation between interviewer preferences.
For human-led interviews: introduce yourself and your role, explain the format and time allocation at the start, follow the rubric question sequence, take timestamped notes referencing specific candidate statements, and reserve five minutes at the end for candidate questions. SHRM has reported that a substantial share of HR managers acknowledge bias influences their evaluations; specific figures vary by study, but the practical implication is the same — a rubric reduces that surface area by requiring evidence-based ratings rather than holistic impressions.
How AI Interview Agents Support Consistent Evaluations
Tools like OnScreen are designed to reduce variability at the stage where it does the most damage: first-round screening. Every candidate receives the same questions in the same sequence, scored against the same model, and evaluation does not vary by interviewer mood or fatigue. Adaptive agents go further by generating follow-up questions based on what the candidate just said or coded, so the interview adjusts to actual performance while still applying the same rubric to everyone.
Research from Glassdoor's Worklife Trends 2024 report found a majority of candidates are comfortable with AI screening provided a human makes the final decision — a useful signal that candidates respond to AI screens better when the human role in the funnel is communicated up front.


Step 7 — Evaluate Candidates Using Data, Not Gut Feel
A frequent failure point in technical hiring is not the interview itself; it is the evaluation afterward. Teams that struggle with how to evaluate developers in interviews consistently identify the same root cause: no shared criteria going into calibration.
From Scorecards to Side-by-Side Candidate Comparison
A clean coding interview evaluation follows three steps: individual scorecard completion before any group discussion, a structured calibration meeting using rubric scores as input, and a documented hiring recommendation that maps back to the competency matrix.
AI-generated transcripts and code playback change what is possible at calibration. A hiring manager who was not in the screening round can review the transcript, see exactly how a candidate handled a specific question, and form an independent view before the panel discussion, rather than hearing a secondhand summary shaped by whoever spoke first.
For teams running assessments alongside interviews, combining assessment scores with interview rubric data gives a multi-signal picture more predictive than any single format alone. HackerEarth's assessment platform pulls both data sets into a single candidate profile, including code quality, plagiarism flags, and rubric-aligned interview scores.
Limitations of AI Interview Agents Worth Naming
AI interview agents are not a universal fit. Worth being honest about the failure modes:
- Training-data bias. Scoring models inherit the biases of the data they were tuned on; rubric design and ongoing audits matter more than vendor marketing suggests.
- Role mismatch. AI agents tend to perform best on well-bounded technical screens (coding, debugging, scoped system design) and less well on highly senior, ambiguous, or culture-heavy rounds.
- Candidate experience variability. Some candidates report discomfort with avatar-led or recorded formats; making the AI step explicit and optional-to-discuss with a human reduces drop-off.
- Identity and integrity edge cases. Even with proctoring and identity verification, no tool is bias-free or cheat-proof; treat AI signal as one input alongside human panels rather than a verdict.
Naming these openly is part of the case for using AI agents only where they add signal — typically the first round — rather than across the entire funnel.
Deliver Feedback and Improve the Candidate Experience
Feedback to rejected candidates feels like optional extra work until you realize every candidate who walks away without it is a potential detractor in a tight engineering community.
Close the loop with every candidate within five business days. For candidates who completed a full technical assessment and interview, provide rubric-referenced feedback: not "you were not quite what we were looking for" but "your solution was correct and your communication was strong; the panel needed more depth on distributed systems trade-offs for this role." That single sentence converts a rejection into information rather than judgment.
AI interview reports make this fast. A hiring manager pulls the evaluation summary, adds one sentence of human context, and delivers actionable feedback in under five minutes instead of synthesizing notes from three different interviewers.
Where AI Interview Agents Fit in the Full Hiring Funnel
Treating AI interview agents as a replacement for the full technical interview process is a common adoption mistake. They are a stage in a multi-signal pipeline, most useful when positioned at the right point in the sequence.
Screening Stage
AI agents handle high-volume first-round screens autonomously. A candidate who applies on Monday can complete a structured technical interview by Tuesday morning, without waiting for a recruiter to find a calendar slot. Time-to-hire gains are largest at this stage because the main bottleneck — scheduling and running screening calls — disappears.
Assessment Stage
Pair AI agents with structured coding assessments for a two-signal evaluation. The assessment provides objective code quality metrics; the AI interview adds conversational signals: how a candidate explains their thinking, handles ambiguity, and responds to follow-up. Together they produce more useful data than either format alone.
Final Interview Stage
Human interviewers use AI-generated transcripts and code playback to run more targeted final-round conversations. Instead of re-covering ground the AI already assessed, the final round focuses on role-specific depth, culture and collaboration signals, and questions only a human conversation can answer.
7 Common Mistakes to Avoid When Conducting Technical Interviews
Gaps between best practice and how technical interviews actually run tend to look similar regardless of company size. Each mistake below is a place where unstructured processes substitute habit for signal.
- Skipping the competency matrix. Questions drift toward what interviewers find interesting, not what the role requires, and post-interview calibration has no anchor.
- Using the same question bank for junior and senior roles. Difficulty should track seniority; using the same questions at every level tests the wrong things at both ends.
- Letting each interviewer freelance their own format. When every interviewer runs a different process, you cannot compare candidates; you are comparing interviewers.
- Prioritizing trick questions over real-world problem-solving. Trick questions test whether the candidate has seen the puzzle before, not whether they can do the job.
- Ignoring communication and collaboration signals. A candidate who writes correct code but cannot explain their reasoning will struggle in code reviews and incident response; communication belongs in the rubric, not as an afterthought.
- Waiting too long to deliver feedback. Candidates who wait two or more weeks will either accept another offer or describe the experience publicly; feedback within five business days is a competitive differentiator.
- Not using AI tools to scale and standardize. Running every first-round screen manually trades hiring capacity for process inertia — a structured AI-led first round frees recruiter and engineer hours for the rounds where human judgment actually matters.
Next steps
A technical interview process that produces consistent, defensible hiring decisions is built from seven repeatable moves: define role competencies with a matrix, choose structured formats matched to role type, prepare rubric-scored questions before interview day, set up a frictionless environment, standardize the first round with an AI interview agent like OnScreen, conduct every interview against the same criteria, and close the loop with specific feedback within five business days.
The recruiters who get the most out of this approach tend to share one habit: they treat the rubric and the AI report as the canonical record of the interview, not the conversation people remember afterward. That single shift — from impressions to evidence — is what makes the process more consistent across candidates than human-led screens alone.
Next step: Book a demo of OnScreen to see how a structured, rubric-applied first-round technical interview runs at scale.
FAQs
How long should a technical interview last?
Coding rounds typically need around 45 minutes; system design rounds benefit from a full 60; AI-led first-round screens often run in the 30–45 minute range because adaptive questioning removes some of the conversational drift in human-led screens. Format determines the right length more than convention does.
If interviews routinely run long, the more likely problem is an underspecified question, not an under-allocated time slot.
Can AI conduct a technical interview?
AI interview agents can run full first-round technical interviews, including adaptive questioning, real-time code evaluation, and structured report generation. They tend to work best at the screening stage where consistency and speed matter most. Human interviewers remain the stronger option for final rounds, where nuanced judgment, culture signals, and relationship-building cannot be automated.
The harder question for most teams is operational: will the panel trust the AI report enough to make calibration decisions from it, instead of re-running its work in person?
What questions should I ask in a technical interview?
Questions should map to the role's competency matrix and cover algorithmic challenges, system design prompts for senior roles, debugging exercises, and domain-specific questions relevant to the team's stack. Avoid anything that rewards memorization over applied thinking.
The most predictive questions are usually the ones that look closest to the actual job — not the cleverest puzzle in the question bank.
How do you evaluate a candidate in a technical interview?
Use a pre-built scoring rubric covering problem-solving approach, code correctness, code quality, communication, and time management, rated on a 1 to 5 scale with behavioral anchors, and complete it individually before any group discussion. Combine human rubric scores with AI-generated evaluation data for a fuller picture.
Rubrics feel like bureaucracy until the first calibration meeting where someone changes their recommendation after hearing the room — at which point you wish every score had been locked in before the discussion started.
How do you reduce bias in technical interviews?
Structure is the most consistent lever available: standardized questions, rubrics with behavioral anchors, and diverse panels reduce the conditions under which bias operates. AI-powered interviews — where the AI applies a fixed rubric and question set to every candidate, trained on the hiring team's own evaluation criteria, with limits around team-fit and senior judgment calls — can add rubric-applied evaluation that doesn't vary by interviewer mood or fatigue. According to Glassdoor's Worklife Trends 2024 research, a majority of candidates are comfortable with AI screening as long as a human makes the final decision.
Bias does not disappear with a rubric; it just has less room to operate without becoming visible in the scores.




