meta_title: "Automated interview tools for technical screening (2025)" meta_description: "Automated interview tools cut first-round screening time and standardize candidate evaluation. Learn how leading teams scale technical hiring without sacrificing quality." read_time: "10 min read" primary_persona: "Recruiter / Technical hiring manager"
Automated interview tools for technical screening (2025)
If you're a recruiter or hiring manager running technical pipelines, first-round screening is likely your biggest bottleneck — not because hiring teams are slow, but because manual screening was never built to handle modern application volume. Companies receive an average of 250 applications per open role (Glassdoor), and engineering roles routinely draw several times that. Automated interview tools — software that screens candidates in the first round without a live interviewer — are how teams now compress that bottleneck.
These tools now handle first-round technical screening with measurable consistency and speed at thousands of companies. The category spans async coding tests, AI-scored video interviews, and AI agents that conduct live adaptive interviews. This article covers what these tools are, how they work, what benefits and risks to expect, and how to evaluate the right platform for your team.
What are automated interview tools?
Automated interview tools are software platforms that screen job candidates without requiring a live interviewer in the first round. They use coding assessments, AI-scored video interviews, or conversational AI agents to evaluate candidates at scale — replacing the repetitive first-round screen so hiring teams can focus on deeper evaluation with candidates who have already proved baseline competency.
Three categories exist, and they are not interchangeable:
- Automated coding assessments: Asynchronous code challenges scored automatically. The AI evaluates correctness against test cases, runtime efficiency, and code structure; it is trained on labeled solution data and is limited to what the test cases cover — it will not catch design issues outside the assessment scope.
- AI video interviews: Recorded responses evaluated by natural language processing and machine learning models for technical accuracy and role-specific competencies. These models are typically trained on labeled interview response data; their limits include sensitivity to accent, audio quality, and response framing, which is why human review of final shortlists is standard practice.
- AI interview agents: Conversational AI that conducts live, adaptive technical interviews in real time — probing weak areas with follow-up questions and generating structured evaluation reports.
The first two are pre-screening tools that filter the funnel before any human time is spent. The third is closer to a first-round technical interview conducted by software.
How automated interview tools differ from traditional screening
| Dimension | Manual phone screen | Automated tool |
|---|---|---|
| Time per candidate | 30–60 minutes active recruiter time | Minutes of setup; zero marginal time per candidate |
| Consistency | Varies by interviewer, day, and mood | Identical criteria applied to every candidate |
| Scalability | Limited by recruiter capacity | Screens hundreds simultaneously |
| Bias risk | High (unconscious, interpersonal) | Lower interpersonal variability — but AI scoring bias remains a risk, dependent on assessment and model quality (see below) |
| Data captured | Notes, impressions | Time-per-question, code metrics, structured scores |
Note: "lower bias" in the table above refers specifically to interpersonal variability between human interviewers. AI scoring models can introduce different forms of bias inherited from training data; see the limitations section.
Why first-round technical screening needs automated interview tools
The volume problem
The math stopped working for manual screening before most teams admitted it. Companies receive an average of 250 applications per open role (Glassdoor); for enterprise technical positions that routinely reaches several thousand. An Ashby analysis of more than 31 million applications found job application volume grew significantly in early 2024. Manual screening at that volume is not a slower version of automated screening — it is a categorically different process.
Inconsistency in evaluation
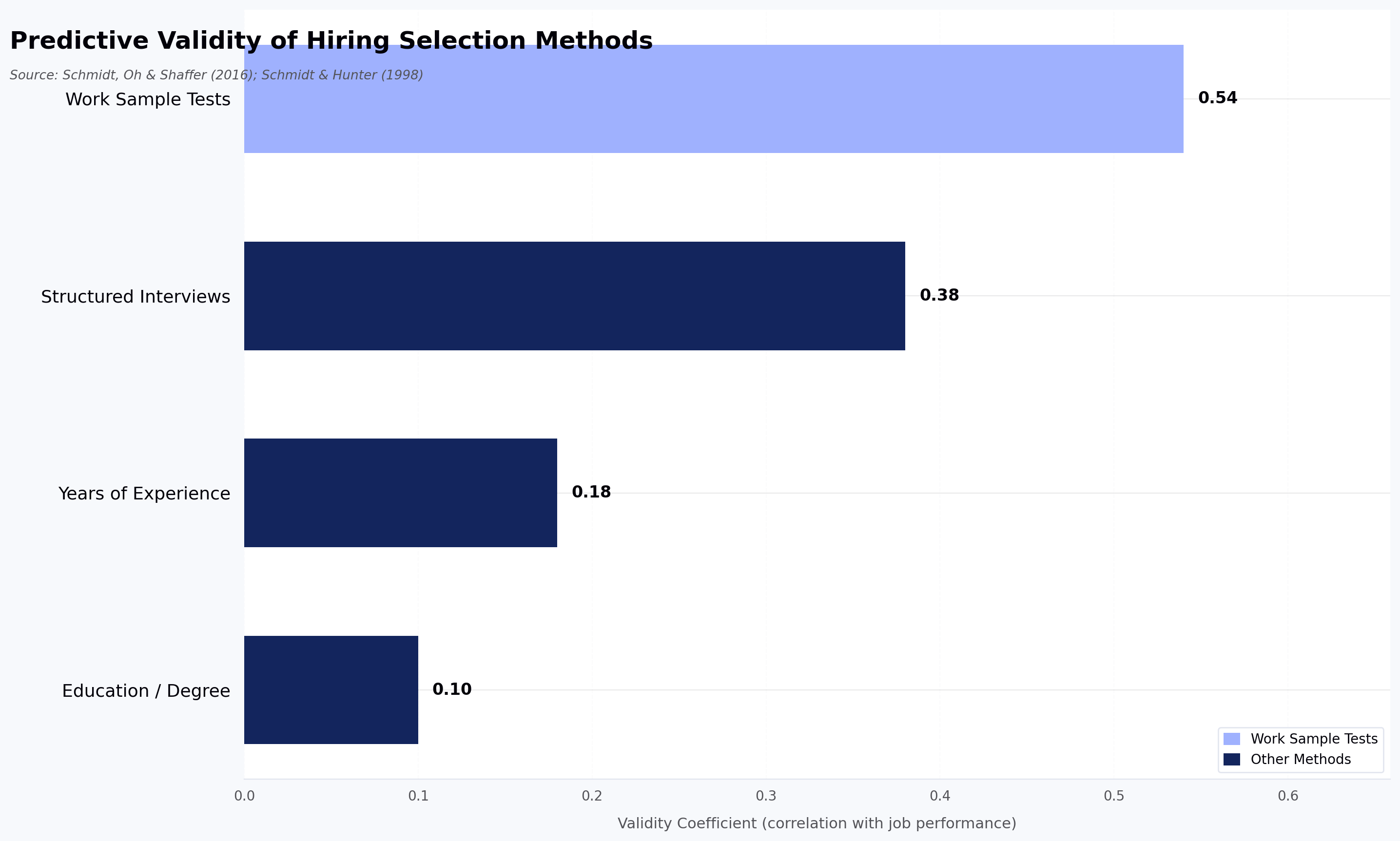
Two recruiters conducting unstructured phone screens will rank the same candidate pool differently — because unstructured interviews have a criterion-related validity of just 0.38, meaning they predict job performance barely better than chance (Schmidt & Hunter, 1998, Psychological Bulletin). Structured interviews with standardized questions reach a validity of 0.51. Automated interview tools enforce identical evaluation criteria for every candidate, producing more consistent evaluations than human-led screens.
Time-to-hire pressure
Engineering roles take an average of 44 days to fill, according to LinkedIn Talent Solutions, and the GoodTime 2025 Hiring Insights Report paraphrases findings that most companies saw fill times increase in 2024. The pressure on time-to-hire is why first-round automation is now a budget priority for many talent teams, even where overall hiring is flat.

How automated interview tools work in practice
Step 1 — Assessment design
The hiring team selects or builds the evaluation — a timed coding challenge in the team's actual stack, multiple-choice questions, system design prompts, debugging exercises, or a combination. Question library depth is the determining factor here: an assessment built for a backend engineer working with distributed systems will produce a meaningfully different shortlist than a generic "software engineer" test. HackerEarth's Skill Assessments cover 1,000+ skills across 40+ programming languages, with role-specific templates deployable in minutes or customizable to the specific problems your engineering team works on — directly addressing the library-depth criterion most evaluations underweight.
Step 2 — Candidate completion
Candidates receive an invitation link and complete the assessment on their own schedule within a deadline. Most platforms include remote proctoring features — browser lockdown, webcam monitoring, copy-paste detection, tab-switch alerts — that maintain integrity without a human proctor. Removing scheduling friction from this stage alone reduces candidate drop-off from processes qualified people find inconvenient.
Step 3 — AI evaluation
Basic implementations of automated interview tools check for correctness. Advanced platforms assess code quality, time and space complexity, edge-case handling, and problem-solving approach — not just whether the answer compiles. The AI scoring is trained on labeled candidate response data; its limits include sensitivity to assessment design quality and an inability to evaluate cultural or contextual fit, which is why a human review step at shortlist stage is standard.
Step 4 — Shortlist generation
The platform generates a ranked shortlist with per-question performance data, time spent, code quality metrics, and aggregate scores. Recruiters move to live interviews with full context on each candidate's specific strengths and gaps — rather than starting from scratch in a 45-minute phone call.
Key benefits of automated interview tools for technical hiring
Faster screening at scale
Automated interview tools enable teams to process candidate volumes that would be impossible to handle through manual phone screens. The throughput effect is most visible in campus drives and high-volume intake periods, where a single recruiter can oversee thousands of evaluated candidates in a window that manual screening could not approach.
Consistent evaluation across candidates
The structured data automated tools produce — identical questions, identical scoring criteria, identical constraints — removes the day-to-day variability that distorts manual phone screens. Where the comparison table above shows this as a dimension, the operational consequence is that two recruiters working different shifts produce shortlists that can actually be compared.
Better candidate experience
Most candidates prefer completing an assessment on their own time over coordinating a 15-minute phone screen that takes three days to schedule. Research from Glassdoor and similar sources indicates many candidates accept AI screening when a human makes the final decision, and process speed influences offer-acceptance rates. The candidate experience benefit is a conversion rate metric, not just goodwill.
Richer hiring data
A phone screen produces notes. An automated interview tool produces time-per-question, code efficiency scores, debugging approach, and problem-solving patterns — structured data that improves shortlisting accuracy now and creates a feedback loop for future hiring cycles. For a deeper look at how this data feeds hiring decisions, see our guide to skills-based hiring.
Freed-up recruiter capacity
When the first-round screen is handled automatically, recruiters stop reviewing coding submissions and start doing the work that actually requires human judgment: selling candidates on the role, managing offers, and building pipeline. Greenhouse and similar talent-tech publishers have reported that recruiters using AI tools spend less time on repetitive review and more on candidate relationships.
Limitations and risks to watch for
Over-reliance on automation
Automated interview tools should filter, not decide. A ranked shortlist is input to a human evaluation, not a substitute for one — final decisions require judgment about cultural fit and communication depth that no automated assessment captures. Hiring managers who insist on human involvement at the final stage (Insight Global) are reflecting a practical reality, not nostalgia.
Candidate perception
Experienced engineers have strong opinions about timed coding tests, and many of those opinions are not positive. A 45-minute algorithm challenge under proctoring conditions does not replicate how anyone actually works. A defensible position here: async coding tests work well for high-volume early-career and campus screening, where the alternative is no screen at all; for senior engineering roles, a conversational AI interview or a live technical screen produces better signal than a timed algorithm puzzle. The mitigation in either case is transparency — explain what the assessment evaluates and what comes next, and pair it with prompt, personal follow-up. See our work on candidate experience in technical hiring for more on this.
Assessment quality matters
A badly designed automated assessment is worse than no assessment — it creates false confidence in a signal that measures nothing useful. The platform provides the delivery infrastructure; the question quality determines what you are actually evaluating. Validated, role-specific question libraries are categorically different from generic question banks, and this distinction is the one most evaluations underweight.
Bias in AI models
AI scoring models inherit the biases of their training data. A model trained primarily on candidates from a particular educational background or geography will favor profiles that resemble that set. Concern about AI inadvertently screening out qualified applicants is widely reported across talent research. Require fairness audit documentation from any platform you evaluate — vendor marketing is not a substitute for published audit results.
What to look for when evaluating automated interview tools
The market for interview automation software has expanded fast enough that AI capabilities now describe tools with very different underlying mechanisms. Evaluate on specifics, not marketing claims.
- Question library depth and customization: Can the technical assessment platform be configured for your actual stack and role mix?
- Scoring transparency: Does the platform explain how scores are generated, or does it produce a number without explanation?
- Proctoring and integrity features: Browser lockdown, webcam monitoring, plagiarism detection, and anomaly flagging are now table stakes for screening software.
- ATS integration: Native integrations with major ATS platforms (verify supported partners with the vendor) keep candidate data synchronized without manual work.
- Candidate experience design: Branded interface, mobile-friendly completion, and automated status communications.
- Reporting and analytics: Exportable scorecards, cohort benchmarking, and pipeline conversion data by assessment type.
- Support for multiple formats: Async coding tests, system design, MCQs, debugging exercises, and AI-led interviews are different tools for different evaluation needs.
Why HackerEarth
Tying back to the question-library-depth criterion above: HackerEarth's Skill Assessments cover 1,000+ skills across 40+ programming languages and are used by 500+ global enterprises for technical screening. OnScreen — HackerEarth's AI interview tool — conducts rigorous, structured technical interviews around the clock using lifelike video-avatar interviewers (an AI-driven simulation of a live interviewer that asks adaptive technical questions and evaluates responses in real time) with built-in identity verification and proctoring, giving recruiters a way to scale first-round screening without scheduling overhead. Check current ATS integration partners directly with the HackerEarth team.
How companies cut screening time with automated interview tools
Industry reporting on early-career hiring programs has documented meaningful efficiency gains from automated video screening at scale. For example, coverage of Unilever's video-assessment program in The Guardian describes the company's use of AI video interviewing across early-career intake; the program has since faced public scrutiny over AI fairness, and the company has modified its use of certain video-analysis features. It is best read as third-party evidence that high-volume automated screening is a category enterprises now operate at scale, rather than as an endorsement of any specific vendor implementation.
A more recent and specific HackerEarth deployment illustrates the same pattern in a technical context: a large Indian IT services employer running engineering campus drives uses HackerEarth Skill Assessments to evaluate tens of thousands of candidates across a single hiring season, with structured per-candidate scoring that downstream interview panels can act on directly. In typical deployments, fast-growing technical teams use automated coding assessments to run campus screening across thousands of applicants in a weekend, a timeline that would take dozens of recruiters to replicate manually. Distributed teams replace timezone-dependent phone screens with async AI interviews that produce better structured data and remove the scheduling delays that cause qualified candidates to accept other offers first.

Frequently asked questions
What are automated interview tools?
Automated interview tools are software platforms that conduct first-round candidate screening across three formats — async coding assessments, AI-scored video interviews, and conversational AI interview agents — without a live interviewer. A common misconception is that these three formats are interchangeable; in practice, async coding tests are best suited to high-volume early-career and campus screening, AI video interviews suit role-mix screening where communication is part of the signal, and conversational AI agents work better for mid-level technical roles where adaptive follow-up questions add signal. Choosing the wrong format for the role is a more frequent mistake than choosing the wrong vendor.
Can automated interview tools replace human interviewers?
No — they handle first-round filtering, not final decisions, and most hiring managers say human involvement remains essential to the final hiring call (Insight Global). The honest framing is that these tools eliminate the part of hiring that consumes the most recruiter time and produces the least reliable signal.
How do automated screening tools reduce hiring bias?
Identical questions and scoring criteria for every candidate remove the variability caused by different interviewers and the interpersonal dynamics that distort unstructured screens (Schmidt & Hunter, 1998). The important caveat: AI scoring models trained on historically skewed data replicate that skew, so published fairness audits are a non-negotiable vendor requirement, not a nice-to-have.
What types of roles benefit most from automated interview tools?
Software engineering, data science, DevOps, and QA benefit most because coding, debugging, and system design can be objectively evaluated at scale. The scalability advantage is most pronounced in high-volume scenarios — campus recruiting, distributed hiring across time zones, and large intake drives where manual screening would require a much bigger team.
How long does it take to set up an automated interview tool?
Pre-built templates deploy in minutes; custom assessments for a specific stack take a few hours; ATS integration typically takes one to two days. The setup cost is front-loaded and small relative to the screening time it replaces from the first cohort onward.
What should I look for in an automated interview platform?
Question library depth and validation, scoring transparency, remote proctoring features, native ATS integrations, candidate experience design, exportable analytics, and support for multiple formats including coding, system design, MCQs, and AI-led interviews. Question library quality is the highest-leverage criterion and the one that gets underweighted most often when teams focus on platform interface instead.
Conclusion
Automated interview tools are not replacing technical interviewers. They are removing the bottleneck that stops hiring teams from reaching the best candidates fast enough — first-round screening that consumes recruiter time, produces inconsistent results, and filters out candidates based on who happened to conduct the screen rather than what the candidate can actually do.
The teams building faster, fairer technical hiring pipelines are the ones that have automated the repetitive first-round screen and redirected human judgment to where it matters: evaluating depth, assessing fit, and convincing qualified candidates that your company is worth joining.
Next steps
See how HackerEarth's Skill Assessments handle first-round technical screening for 500+ global enterprises. Contact the HackerEarth team to discuss trial access and pricing for your hiring volume.