10 best technical screening services to evaluate developer skills in 2026
Technical screening services are platforms that evaluate candidates' programming, debugging, and system design skills through standardized or customizable tests — before recruiters or engineers commit time to interviews. For teams hiring developers at any volume, these technical screening services have become the filter between an applicant pool and an interview calendar, replacing resume-based guesswork with measurable signal.
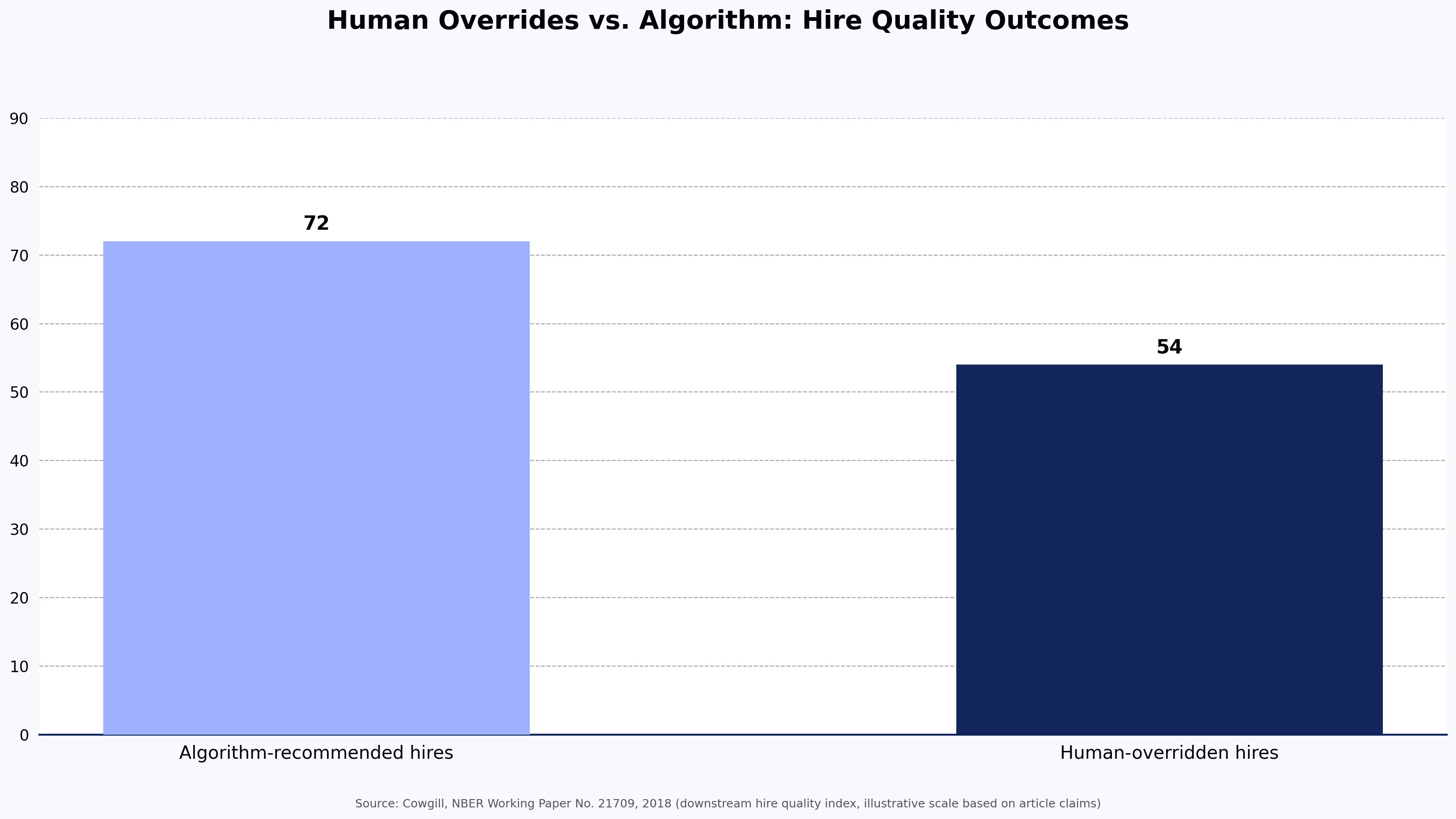
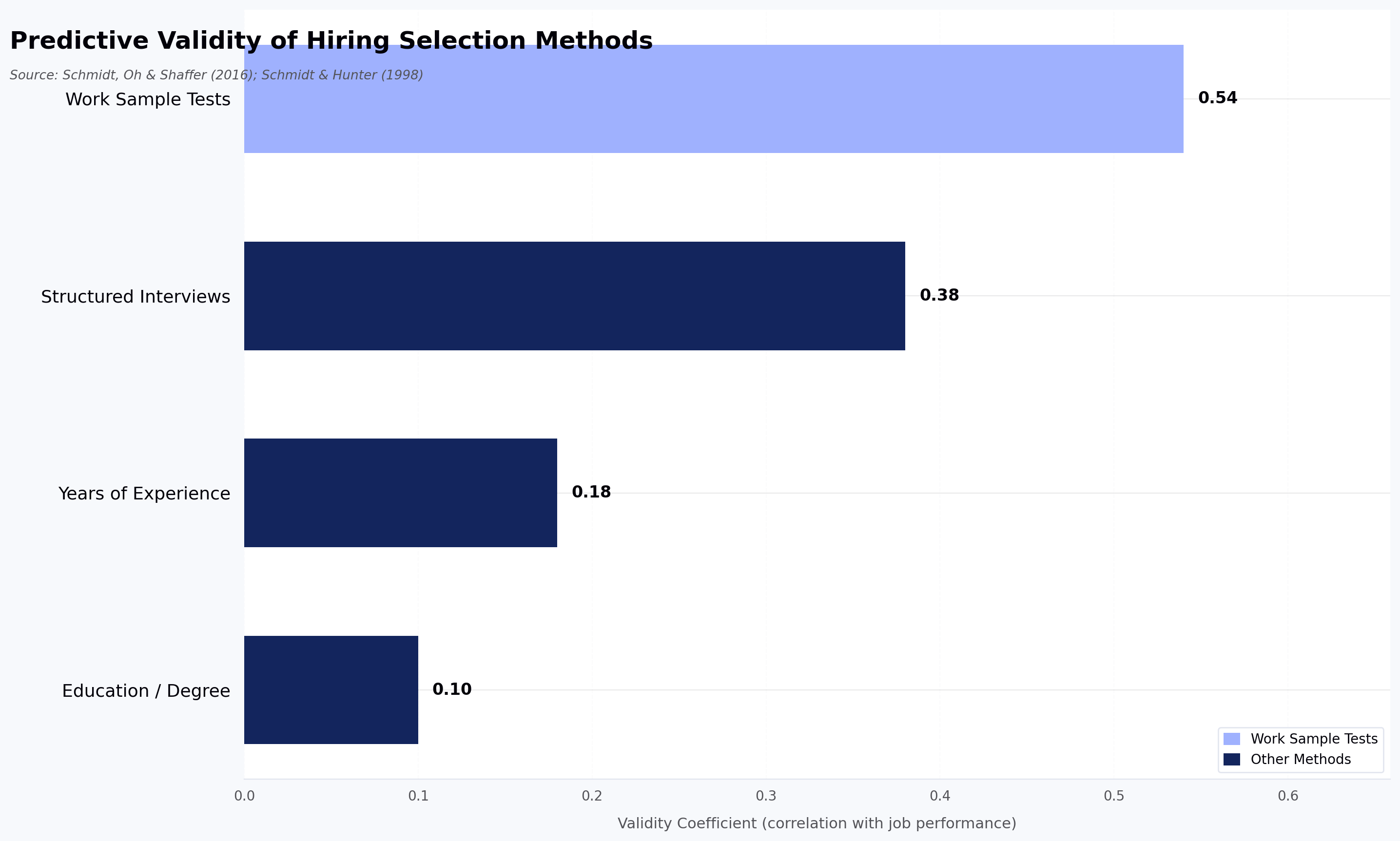
A bad technical hire costs at least 30% of that employee's first-year salary, according to a frequently cited U.S. Department of Labor figure, and that number assumes a clean exit. For senior engineering roles, the real damage — in team disruption, re-hiring time, and lost momentum — runs considerably higher. The problem is not just that bad hires happen. It is that most hiring processes are built on signals that do not actually predict whether someone can write code: resumes measure career history, unstructured interviews measure how well people interview.
This guide covers 10 technical screening services evaluated on assessment depth, AI capabilities, proctoring, candidate experience, ATS integrations, and pricing — for recruiters and hiring managers who want faster, more defensible technical hiring decisions.
What are technical screening services?
The simplest way to think about technical screening services is as the filter between your applicant pool and your interview calendar. Also called developer screening services, technical evaluation services, or programming assessment tools, these platforms evaluate candidates' programming, system design, and debugging skills through standardized or customizable tests — online coding tests for hiring, project-based tasks, live collaborative sessions, or AI-scored async video interviews — before any recruiter or engineer has to get on a call.
The distinction from generic pre-employment testing matters: a personality test will not tell you whether a candidate can debug a memory leak, and a cognitive assessment will not tell you whether they can design a REST API. Technical screening services are built specifically for code.
How we evaluated these technical screening platforms
Each platform in this list was evaluated both as a developer assessment software solution and as a technical screening service, across eight criteria:
- Assessment library depth and customization
- AI and automation features
- Anti-cheating and proctoring capabilities
- Candidate experience and interface quality
- ATS and HRIS integrations
- Pricing model transparency
- Scalability for enterprise vs. SMB
- Reporting and analytics
| Platform | Best For | Key Assessment Types | AI Features | Integrations | Free Trial |
|---|---|---|---|---|---|
| HackerEarth | Enterprise developer hiring at scale | Coding, MCQ, system design, live coding | AI assessment generation, AI-driven async interviews (OnScreen); proctoring available separately | Greenhouse, Lever, Workday, iCIMS | Contact vendor |
| HackerRank | Enterprise with dedicated tech recruiting | Coding, take-home, CodePair live | AI plagiarism detection, AI interviewer | Greenhouse, Lever, Workday | Yes (14-day) |
| Codility | Task-based algorithmic screening | CodeCheck, CodeLive, algorithmic tasks | AI-assisted engineering assessment | Greenhouse, Lever, custom API | Yes |
| CodeSignal | Standardized benchmark scoring | Certified assessments, IDE-based coding | AI scoring engine, question leak mitigation | Greenhouse, Lever, Workday | Yes |
| CoderPad | Live pair programming interviews | Live coding, take-home, 30+ languages | Limited AI features | Greenhouse, Lever, iCIMS | Free plan |
| TestGorilla | Broad pre-employment tech + non-tech | Coding, cognitive, personality, video | Anti-cheating, video responses | Greenhouse, Lever, Workday | Yes |
| iMocha | Hiring + internal upskilling combined | 3,000+ skill tests, AI-LogicBox coding | AI skills inference, talent analytics | Greenhouse, Workday | Free plan |
| Coderbyte | Startups and SMBs, junior to mid-level | 300+ coding challenges, custom tests | Basic plagiarism detection | Limited | Yes (14-day) |
| DevSkiller | Project-based realistic work simulation | Project tasks, auto-scoring, tech-specific | Automated scoring | Greenhouse, Lever, ATS API | Yes |
| Vervoe | AI auto-ranking, reduced manual review | Tasks, simulations, custom, video responses | AI auto-grading, AI candidate ranking | Greenhouse, Lever | Yes |
1. HackerEarth
Overview
HackerEarth is worth considering when you want async screening and live interviews in one place rather than running two separate products for the same hiring pipeline. Trusted by 500+ global enterprises including Google, Microsoft, Elastic, Flipkart, and Brillio, it covers the full developer screening workflow without requiring coordination between tools.
Key features
The assessment library spans 1,000+ skills across 40+ programming languages, which means a developer skills assessment for almost any role type — front-end, back-end, DevOps, data science, machine learning — can be built without writing questions from scratch. Hiring teams can pull from the library or use AI-powered assessment generation, which uses a job description as input to draft questions matched to the role; the output is editable, and human review is recommended before deployment. HackerEarth's technical assessment platform handles multiple-choice questions and open-ended coding challenges in the same session.
FaceCode, HackerEarth's live coding interview product, gives interviewers a collaborative coding environment with real-time evaluation; for a deeper review of live coding interview platforms compared, HackerEarth maintains a category overview. OnScreen, HackerEarth's AI-driven async interview product launched in April 2026, runs first-round screens on the candidate's own schedule, removing the scheduling step that typically extends time-to-hire at volume. OnScreen scores responses against rubric criteria; final hiring decisions remain with the human reviewer. Proctoring runs image, audio, and video monitoring simultaneously with full session replay. Native ATS integrations include Greenhouse, Lever, Workday, SAP SuccessFactors, and iCIMS.
Best for
Mid-market to enterprise teams running simultaneous developer hiring across multiple roles who need async screening and live interviews from a single platform.
Limitation
Smaller teams with low hiring volume and no need for live coding interviews will not use enough of the feature set to justify the full-tier pricing.
Pricing
Custom pricing based on volume; contact vendor for current trial terms.
2. HackerRank
Overview
HackerRank is one of the most widely recognized names in the category. The company has publicly cited more than 2,500 enterprise customers, and its brand recognition on the candidate side is a real recruiting advantage — developers tend to take assessments more seriously on platforms they have already used to practice.
Key features
The platform covers coding challenges, take-home projects, and CodePair live interviews in one product. Its AI stack includes keystroke analysis, LLM-generated answer detection, and Proctor Mode with session replay. Publicly listed pricing (as of late 2025) starts at $165 per month for Starter ($1,990 annually) and $375 per month for Pro ($4,490 annually); verify current pricing with the vendor.
Best for
Enterprise teams with dedicated technical recruiting functions that need a high-volume platform with mature AI integrity features and strong developer-community reputation.
Limitation
Pricing escalates quickly at higher candidate volumes, and the platform carries a steeper recruiter learning curve than newer tools.
3. Codility
Overview
Codility suits teams that want rigorous task-based assessment and do not mind that the platform has a narrower scope than full-stack hiring tools. It has been listed on G2 among leading technical skills screening platforms in Europe (rankings update regularly; verify current standing on G2).
Key features
CodeCheck handles automated pre-built coding assessments, CodeLive supports real-time interviews, and the COMPASS benchmark evaluates AI-generated code on correctness, efficiency, and quality — one of the first platforms to directly assess how candidates work alongside AI tools. Codility's published pricing starts at approximately $100 per month for low volume (verify current rates with vendor).
Best for
Companies prioritizing task-based code-quality assessment over MCQ formats, particularly where real-world engineering complexity is the deciding signal.
Limitation
Language coverage is narrower than the broadest platforms in this list, and async interview capabilities lag purpose-built async tools.
4. CodeSignal
Overview
CodeSignal suits teams that need a scoring framework that will hold up to scrutiny — its Certified Assessments are described by the company as backed by extensive research and provide independently validated benchmarks that make candidate comparisons defensible over time (verify current research-hour figures with the vendor).
Key features
The full IDE-style environment mirrors actual development conditions. An AI scoring engine flags efficiency and code quality beyond just correctness. A proactive question leak mitigation system retires and rotates questions continuously, which is a meaningful integrity advantage at enterprise scale. Custom enterprise pricing required.
Best for
Organizations where standardized scoring benchmarks and legal defensibility are priorities, particularly for large candidate pipelines compared across multiple hiring cycles.
Limitation
Assessment customization is more constrained than open-ended platforms.
5. CoderPad
Overview
CoderPad is a live interview tool used by thousands of organizations including Netflix, Shopify, and Databricks per CoderPad's marketing, with a reputation for interviewer-friendly UX — which matters because a poor interview interface creates friction for both sides.
Key features
The environment supports 30+ programming languages with real-time execution, a drawing tool for architecture discussions, and session playback so interviewers can review candidate reasoning afterward. Take-home projects extend it to async formats. CoderPad's published pricing lists a Starter plan at $100 per month for five tests (verify current pricing with vendor).
Best for
Teams where live coding interview quality is the primary investment and candidate experience during the interview is a genuine recruiting differentiator.
Limitation
CoderPad does not replace a pre-screening platform — most teams using it still need a separate tool for top-of-funnel filtering.
6. TestGorilla
Overview
TestGorilla is a generalist option when technical skills are one ingredient in the evaluation rather than the whole recipe — it handles coding alongside cognitive, personality, and culture-fit assessment in one session.
Key features
The library covers 400+ assessments spanning coding challenges, cognitive ability, personality profiles, culture-fit tests, and video responses. Anti-cheating includes webcam monitoring and IP tracking. Pricing is publicly listed and starts at a functional free tier.
Best for
Companies screening for both technical and non-technical competencies simultaneously, where a broad combined signal is more useful than deep technical depth.
Limitation
For senior or specialized engineering roles requiring advanced DSA, system design, or DevOps evaluation, TestGorilla's technical depth is lighter than purpose-built developer screening platforms.
7. iMocha
Overview
iMocha is worth considering when your organization wants hiring assessment data and internal development data living in the same place — one skills layer rather than two separate tools with incompatible reports.
Key features
The platform offers more than 3,000 skill tests including the AI-LogicBox coding engine. Talent analytics dashboards compare candidates against both internal competency frameworks and external benchmarks. Assessment data can feed directly into learning management systems. Integrations include Greenhouse and Workday.
Best for
Organizations combining external technical hiring with internal skills-gap analysis, where a unified skills intelligence layer across both use cases is the goal.
Limitation
The interface feels less modern than newer entrants, and the workflow leans toward HR generalists rather than developer hiring specialists.
8. Coderbyte
Overview
Coderbyte is a practical starting point for startups that need to filter developer candidates without committing to enterprise pricing — it does the basics well at a price point smaller teams can absorb.
Key features
The library includes 300+ coding challenges, custom assessment creation, and plagiarism detection. According to Coderbyte's published pricing (as of late 2025), pay-as-you-go runs approximately $10 per candidate and the monthly plan starts at $199 (verify current rates with vendor). Starter templates for common roles reduce setup time.
Best for
Startups and SMBs hiring junior to mid-level developers on a budget, where basic automated screening and manageable candidate experience are the priorities.
Limitation
Advanced proctoring, AI-driven analytics, and deep ATS integrations are absent. Growing teams tend to outgrow Coderbyte faster than they anticipate.
9. DevSkiller (now part of TalentBoost)
Overview
DevSkiller's RealLifeTesting methodology is genuinely different from the rest of this list: candidates work on project-style tasks that simulate actual job work rather than abstract algorithm challenges, which changes what the assessment is measuring.
Key features
Project-based assessments cover database work, API development, and front-end implementation with auto-scoring and detailed technical breakdowns by skill area. Tasks are mapped to specific technologies and frameworks. ATS integrations include Greenhouse, Lever, and a custom API.
Best for
Companies that want candidates to demonstrate they can do the work rather than solve a puzzle, particularly for full-stack or domain-specific roles where contextual problem-solving matters more than algorithmic speed.
Limitation
The question library is smaller than category leaders, high-volume first-round screening is not the platform's strength, and the TalentBoost acquisition makes roadmap visibility harder to gauge.
10. Vervoe
Overview
Vervoe automates the part of screening that burns the most recruiter time: the initial review pass, where someone has to look at every submission and decide what to do with it.
Key features
AI auto-grading scores text, code, and video responses. An AI ranking engine surfaces the highest-predicted-fit candidates for human review. Immersive task simulations present realistic job scenarios rather than abstract tests. Customizable branding supports an on-brand candidate experience. ATS integrations include Greenhouse and Lever.
Best for
Teams where reducing manual review time is the primary goal and AI-driven candidate shortlisting is the preferred workflow.
Limitation
Technical depth for developer-specific roles is lighter than purpose-built coding platforms, and live coding capabilities are minimal.
How to choose the right technical screening service
Picking the wrong technical screening service is easy when you are evaluating by feature count. The more useful question is what your actual hiring pipeline looks like.
Define your hiring volume and roles
Volume is the first filter. High-volume pipelines need automation, async capabilities, and ATS integration that does not create more work than it saves. Lower-volume teams usually benefit more from assessment quality and interview environment than throughput features.
Prioritize assessment depth vs. breadth
For dedicated technical roles, a platform with deep language support and project-based tasks will produce better signal than a generalist tool. If you need technical and soft-skill evaluation in the same session, TestGorilla or iMocha handle that combination more effectively than pure developer screening platforms.
Evaluate candidate experience
The candidates most likely to abandon a poorly designed or overlong assessment are usually the candidates with the most options. HackerEarth's guidance on how to improve the candidate experience covers how to reduce drop-off at each funnel stage without sacrificing screening rigor.
Check integration compatibility
A screening tool that does not connect with your ATS turns time savings into manual data entry. Confirm the integration is tested and working, not just listed on the feature page.
Consider async vs. live screening needs
For teams new to technical pre-screening, starting with code screening platforms that handle top-of-funnel filtering before investing in live interview infrastructure is the more cost-efficient path. Some platforms — HackerEarth among them — handle both async and live in one product; CoderPad is live-focused; Vervoe is async-focused.
Review anti-cheating and proctoring features
Developer use of generative AI tools is widespread — Stack Overflow's 2024 Developer Survey reported that around 76% of developers use or plan to use AI tools in their development process. Single-method proctoring is increasingly insufficient at that level of background AI use. Look for session replay, behavioral monitoring, and AI-specific plagiarism detection. HackerEarth's guide to remote proctoring for online assessments explains how to run integrity monitoring without making candidates feel adversarially monitored.
One contested point worth naming directly: AI proctoring is useful but not a complete answer. Behavioral monitoring catches some forms of cheating but cannot reliably detect a candidate using a second device with an LLM. Teams that take integrity seriously usually pair proctoring with assessment design choices — rotating questions, project-based tasks, and live follow-up rounds — rather than treating monitoring tools as the sole control.

Key trends in technical screening services for 2026
The category is moving faster than most HR technology segments, and four shifts will shape which platform decisions hold up heading into 2026.
AI-generated adaptive assessments are becoming a baseline expectation rather than a differentiator. Hiring teams now expect to describe a role and receive a draft assessment they can review and edit. Platforms that still require fully manual question selection are falling behind on speed-to-deploy.
Async AI-driven screening is replacing the recruiter phone screen as the first filtering step. Platforms with AI-driven async interview products — HackerEarth's OnScreen is one example — let candidates complete a technical screen without a human on the other end, removing one of the most persistent scheduling bottlenecks in technical hiring pipelines. The honest caveat: async AI scoring works well for structured technical evaluation and less well for assessing communication nuance, which is why most teams still pair it with a human round.
Skills-based hiring tools that include validated technical assessments are well-positioned as degree requirements continue falling. According to LinkedIn's Workforce Report and Future of Work data, the share of U.S. paid job posts not requiring a four-year degree has risen meaningfully since 2020 — around 26% of postings, up roughly 16 percentage points over that period in LinkedIn's reporting. Remote technical screening platforms that scale efficiently become more valuable as candidate pools grow larger and credentials become less reliable as filters.
Candidate experience has become a competitive differentiator. With SHRM's reported average time-to-fill of around 44 days for technical roles, a clunky or opaque assessment is a genuine reason for strong candidates to withdraw.

Conclusion / Final verdict
The right technical screening service is the one that fits your actual pipeline, not the one with the most features on a comparison chart.
For enterprise teams needing async pre-screening, live interviews, and proctoring in a single product, HackerEarth is a strong option. For teams focused purely on live coding interview quality, CoderPad delivers an experience that is hard to match in that specific context. For organizations that need technical and non-technical evaluation in the same workflow, TestGorilla is the practical choice. Codility and CodeSignal both stand out where benchmark rigor and defensibility matter most, and DevSkiller is hard to beat on project-realistic tasks.
Schedule a demo of HackerEarth Assessments to see how async screening with OnScreen, live coding interviews with FaceCode, and AI-assisted assessment generation fit into your next hiring cycle.
Frequently asked questions
What is a technical screening service?
A technical screening service evaluates candidates' coding and engineering skills through standardized assessments or live interviews before any recruiter or engineer time is committed. It is the difference between knowing a candidate can code and hoping they can based on a resume.
How do technical screening tools reduce time-to-hire?
The mechanism is sequence, not magic: async assessments and automated scoring move the first technical filter ahead of recruiter scheduling, so candidates progress (or drop out) before a calendar invite is ever sent. The biggest practical gain for most teams is removing the back-and-forth around phone-screen scheduling, which is where days typically leak out of the pipeline.
What types of assessments do technical screening platforms offer?
Common formats include MCQs, timed coding challenges, project-based tasks, system design prompts, live pair programming, debugging exercises, take-home assignments, and AI-scored async video interviews. Most platforms now support several of these in a single session, which is worth verifying before you commit.
Are technical screening services fair?
Standardized assessments remove some of the credential and first-impression bias that dominates resume screening, giving non-traditional candidates a clearer path to demonstrate skill. They are not bias-free: poorly designed or unvalidated questions can introduce different biases (cultural references in prompts, time pressure that disadvantages certain groups, accessibility gaps in proctoring). Skills-based hiring reduces some sources of bias and surfaces others — picking a platform with a maintained, job-relevant question library and accessibility options matters more than most buyers realize.
How much do technical screening platforms cost?
Self-service SMB plans typically run $100 to $500 per month, enterprise pricing starts around $10,000 per year, and most platforms offer a free trial or limited free tier. The pricing spread is wide enough that clarifying volume needs before vendor conversations will save significant negotiation time.
Can technical screening tools integrate with my ATS?
Most major platforms integrate natively with Greenhouse, Lever, Workday, iCIMS, and SAP SuccessFactors, but "listed as an integration" and "actually tested and working" are different things. Confirm the data flows correctly in a trial before signing.