Best Leadership Assessment Tests for Executives (2026)
Most leadership assessments sold to enterprises today were designed before remote work, before AI-augmented decision-making, and before the half-life of "strategic skills" reportedly shrank from a decade to about five years, according to the World Economic Forum's Future of Jobs Report 2023. The frameworks still hold up. The way you should use them does not.
This guide covers the seven leadership assessment tests that still produce defensible signal in 2026 — what each measures, where it fails, and how to combine them without overspending or over-testing your bench. It is written for CHROs, Heads of People Analytics, and L&D leaders running succession planning, executive hiring, or capability programs at scale — focused on program design, defensibility, and tiering rather than instrument-by-instrument administration detail.
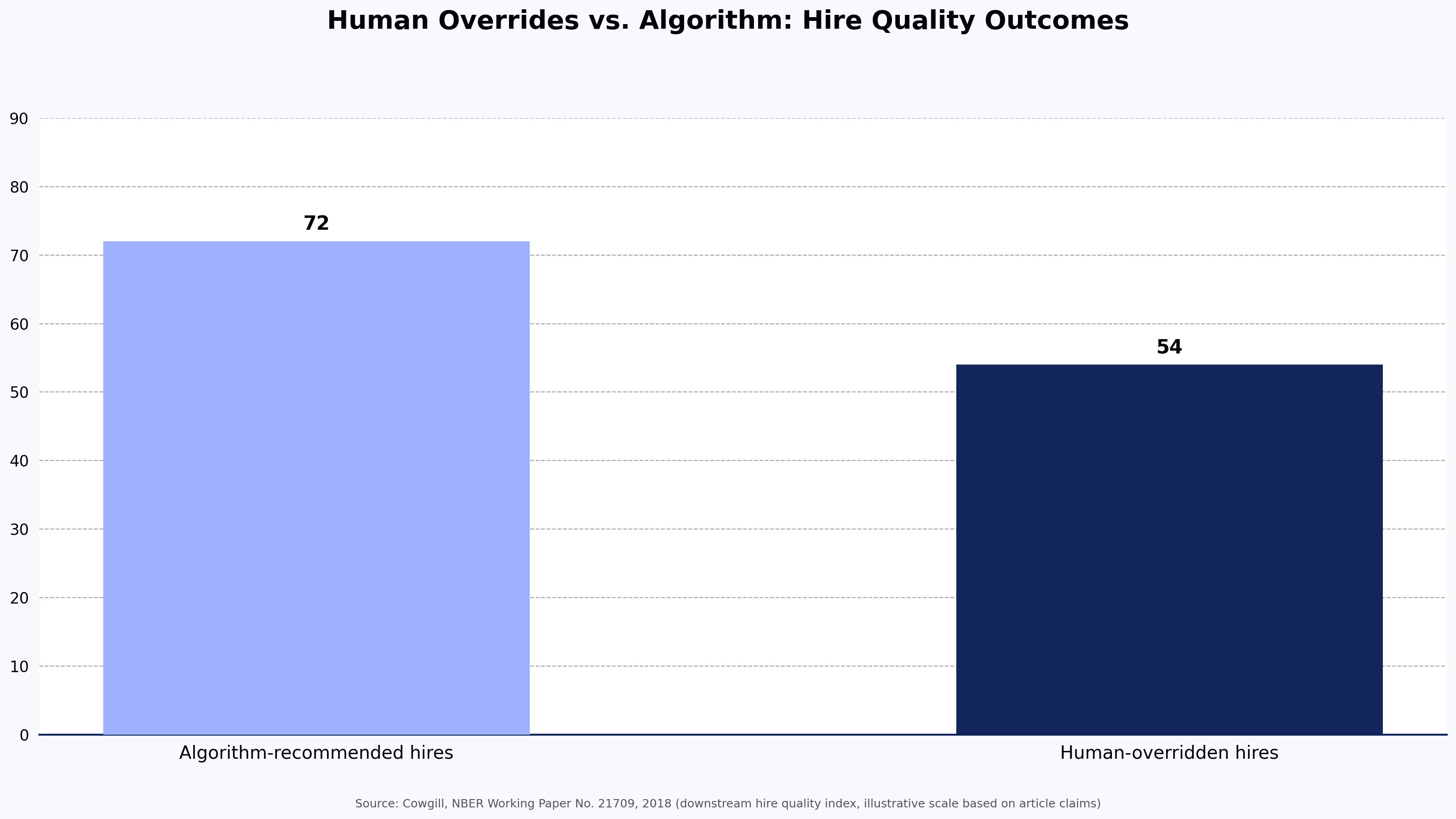
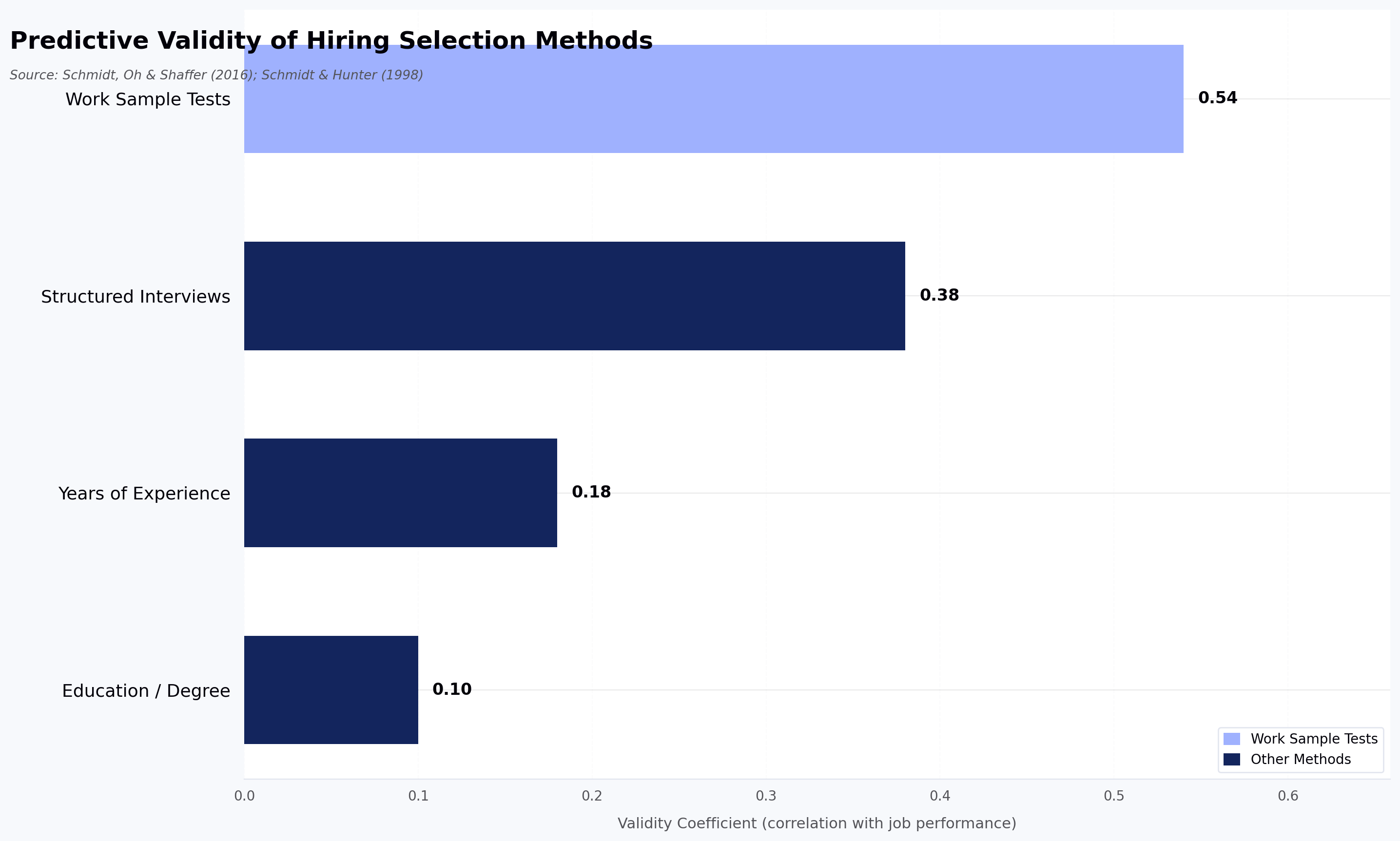
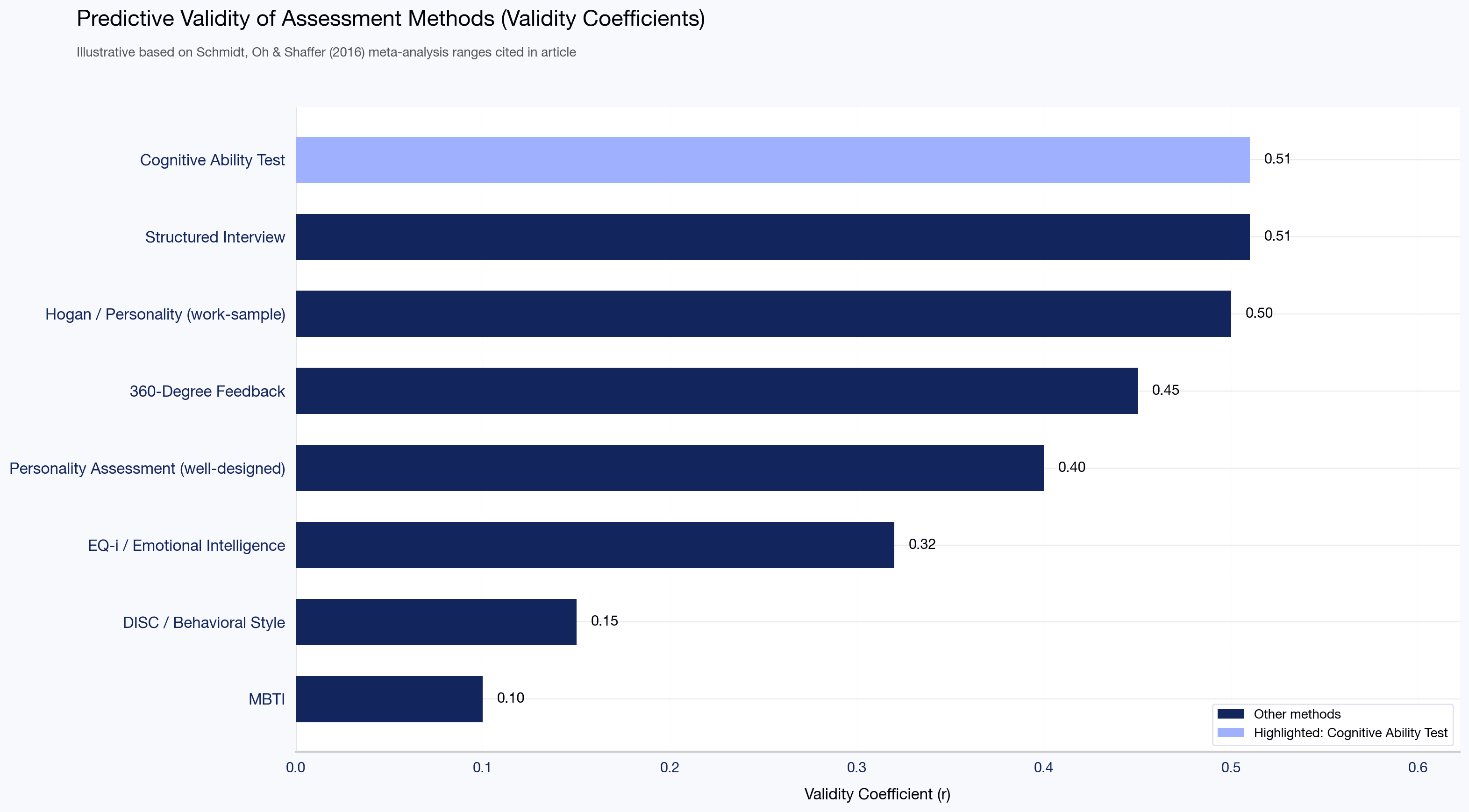
A working assumption before we start: no single leadership assessment test predicts leadership success on its own. Research on validity coefficients is reasonably consistent — well-designed assessments typically correlate with on-the-job performance in the 0.3 to 0.5 range, per the Schmidt, Oh, & Shaffer (2016) update to the classic Schmidt & Hunter meta-analysis. That is useful signal, not certainty. Programs that treat any one score as a verdict end up defending decisions they cannot defend.
What a leadership assessment test actually measures in 2026
A leadership assessment test is a structured evaluation — typically combining self-report, multi-rater feedback, and situational judgment — that produces comparable data about how a person leads, where they will struggle, and what they value. The strongest leadership assessment tests measure traits and behaviors that are stable enough to predict future performance but specific enough to coach against.
What has changed since 2020 is the surrounding context. Three shifts matter for how CHROs and program owners should select and tier these tests:
- Multi-rater data is no longer optional for senior roles. Self-report alone, especially at the executive level, is the weakest version of these tools. Pair every personality-based instrument with structured feedback.
- Derailment risk has overtaken "potential" as the dominant question. Boards now ask "what could go wrong with this leader" more than "is this leader high potential." Assessments that surface dark-side traits earn more budget than those that don't.
- Skills-based mobility puts pressure on assessment cost-per-head. If you are running leadership programs across thousands of mid-managers, executive-grade instruments are too expensive to scale. You need a tiered approach — a question the skills-based hiring approach is increasingly built to answer.
The seven instruments below are the ones that hold up under both scrutiny and scale.
.png)
1. The Hogan Leadership Forecast Series
The Hogan Leadership Forecast Series is a three-part personality assessment designed for senior leadership selection and succession planning, and the reason it remains defensible is unfashionable: it measures what goes wrong. The series covers the Hogan Personality Inventory (HPI), the Hogan Development Survey (HDS), and the Motives, Values, Preferences Inventory (MVPI). Together, these cover everyday strengths, derailment risks under stress, and underlying values.
What it measures well: - Bright-side traits (HPI) that predict day-to-day effectiveness - Dark-side traits (HDS) that emerge under pressure — the "derailers" - Value alignment (MVPI) with organizational culture
Where it falls short: - Cost. Enterprise pricing for the full Hogan battery with a certified debrief varies by vendor and region and is not published publicly; CHROs evaluating it should request a direct quote from Hogan Assessments or an authorized distributor. It is not a tool for the broader manager population at scale. - Time. Typically two to three hours of candidate time plus a debrief, depending on which sub-instruments are administered. - It produces a long report. Without a trained debriefer, the data does not become decisions.
Best use case in 2026: Pre-promotion assessment for VP and C-suite roles, succession-planning slates for the top three layers, and post-hire executive coaching. Hogan is over-specified for first-line manager decisions.
2. The Leadership Practices Inventory (LPI)
The Leadership Practices Inventory (LPI), developed by Kouzes and Posner, is a 360-degree leadership assessment test that evaluates behavior against five practices: Model the Way, Inspire a Shared Vision, Challenge the Process, Enable Others to Act, and Encourage the Heart. The self-score is meaningless without the rater scores.
What it measures well: - Observable leadership behavior, not personality traits - Gap between self-perception and how others experience the leader - Concrete coaching targets ("you are scoring low on recognition — here is what that looks like in a one-on-one")
Where it falls short: - It assumes the person is already in a leadership role with raters who can evaluate them. Not useful for first-time-manager identification. - The five practices skew toward inspirational and people-centric leadership. Operating leaders running technical functions sometimes score artificially low without that being a real problem.
Best use case in 2026: Cohort-based leadership development for mid-level managers, with a re-assessment 9–12 months later to measure behavior change. The before/after delta is what makes the budget defensible to a CFO.
3. The DISC Personality Assessment
DISC is a behavioral-style assessment that categorizes people across Dominance, Influence, Steadiness, and Conscientiousness, and is best treated as a vocabulary tool rather than a selection instrument. It is the most over-used assessment in this list — most organizations would get the same value from a one-hour team conversation. The instrument's real strength is accessibility, not depth.
What it measures well: - Communication style differences within teams - Quick self-awareness for entry-level and mid-level managers - Conflict-pattern recognition in working sessions
Where it falls short: - Negligible predictive validity for leadership performance - Easily gamed — candidates know what the "right" answers look like for the role - The four-quadrant simplicity flattens real differences between people
Best use case in 2026: Workshop scaffolding and team-building, not selection or succession. If you are using DISC scores in a promotion decision, stop.
4. The EQ-i 2.0 Emotional Intelligence Assessment
The EQ-i 2.0 is a self-report emotional intelligence assessment developed from Reuven Bar-On's model (often confused with Daniel Goleman's separate framework). It measures EI across self-perception, self-expression, interpersonal skills, decision making, and stress management. Some research suggests a link between EI scores and leadership effectiveness — for example, Miao, Humphrey, & Qian's (2018) meta-analysis in the Journal of Organizational Behavior on EI and transformational leadership — though the construct remains contested in academic psychology (see critiques from Locke, 2005, and Antonakis and colleagues).
What it measures well: - Self-awareness and impulse control under pressure - Empathy and interpersonal effectiveness - Coachability — leaders who score low on self-perception often resist development
Where it falls short: - Self-report instrument with predictable social-desirability bias - Does not measure cognitive ability or strategic judgment - The construct of "emotional intelligence" remains contested — treat scores as one input, not a verdict
Best use case in 2026: Executive coaching engagements, M&A leadership integration, and roles where the previous leader failed on interpersonal grounds. The 360 version reduces self-report bias materially.
5. The CliftonStrengths Assessment
CliftonStrengths is a strengths-based development assessment from Gallup that surfaces a leader's top five themes from a list of 34. It is the most positively framed instrument on this list and the most useful for retention conversations — but it is not a selection tool.
What it measures well: - Natural patterns of thought and behavior the leader gravitates to - Vocabulary for development conversations and team composition - Engagement and self-direction inputs
Where it falls short: - By design, it does not surface weaknesses or risks. A leader can be a strong Strategic-Achiever-Learner-Focus-Responsibility and still derail spectacularly under pressure. - Themes are stable but the "top five" framing can lock people into identity claims that limit growth. - Validity for selection is weak. Gallup itself positions the tool for development, not hiring.
Best use case in 2026: Internal mobility conversations, team composition exercises, and onboarding for newly promoted managers. Pair it with a derailer-focused instrument like Hogan for any senior decision.
6. The MBTI (Myers-Briggs Type Indicator) leadership test
The MBTI is a personality preference assessment that sorts people into 16 types across four dichotomies. It is the most popular assessment in this list and the most criticized. The academic consensus is that MBTI has limited test-retest reliability — some studies have found a meaningful share of respondents receive a different type on retest over short time periods — and limited predictive validity for job performance.
It appears here because practitioners still encounter it widely and because the conversations it generates often produce value the instrument itself does not.
What it measures well — with caveats: - A vocabulary for individual differences that non-HR audiences accept - Self-reflection prompts in coaching settings - Surface-level team communication patterns
Where it falls short: - Type boundaries are arbitrary — small score differences flip people between types - Not appropriate for selection, succession, or any high-stakes decision - Reinforces fixed-identity thinking ("I'm an INTJ, that's why I don't do feedback") that good development work tries to dismantle
Best use case in 2026: Informal coaching conversations and self-reflection workshops. If your leadership program's centerpiece is MBTI, your program is dated.
7. The 360-Degree Leadership Feedback Assessment
A 360-degree leadership assessment is a method, not a single instrument — it gathers ratings from the leader's manager, peers, direct reports, and sometimes external stakeholders. It produces the most actionable single source of leadership data when done well, and the most damaging data when done badly.
What it measures well: - Behavior as experienced by the people who actually work with the leader - Self-awareness gaps (where the leader's self-rating diverges from rater scores) - Specific incidents and patterns that anchor coaching
Where it falls short: - Rater bias, recency effects, and workplace politics all contaminate the data - Anonymous comments can be weaponized when the relationship is already broken - Without a trained debriefer, leaders read the report defensively and learn nothing
Best use case in 2026: Annual development for senior leaders, post-promotion check-ins at 6 and 12 months, and any executive coaching engagement that lasts longer than three months. Use a validated instrument (Korn Ferry Voices, Center for Creative Leadership Benchmarks, or the LPI 360) rather than a bespoke survey — internal questions will not have the validity work behind them.
Choosing the right leadership assessment
| Assessment | Best for | What it measures | Where it fails |
|---|---|---|---|
| Hogan Leadership Forecast | Executive hiring, succession planning | Personality, derailers, values | Cost, time, requires trained debriefer |
| LPI | Mid-manager development cohorts | Observable leadership behavior | Not for selection or potential ID |
| DISC | Team workshops, communication training | Behavioral style | Low predictive validity |
| EQ-i 2.0 | Executive coaching, interpersonal failure modes | Emotional intelligence | Self-report bias, no cognitive measure |
| CliftonStrengths | Mobility conversations, team composition | Natural talent themes | Does not surface risks |
| MBTI | Self-reflection workshops | Personality preferences | Weak reliability, not for selection |
| 360-degree feedback | Senior development, coaching engagements | Rater-observed behavior | Bias, requires structured debrief |
A practical rule: use no more than two instruments per decision. Stacking five assessments on one candidate produces report fatigue and rarely improves the call. Combinations commonly reported in enterprise practice include Hogan plus 360 for executive decisions, LPI plus EQ-i 2.0 for mid-manager development, and CliftonStrengths plus a structured manager conversation for internal mobility. As one anonymized example, a BFSI client running a top-three-layer succession program reported a measurable reduction in first-year executive derailment after layering a Hogan-plus-360 design over their existing internal slate review.
Where leadership assessment fits into broader skills strategy
For CHROs and Heads of People Analytics running skills-based organization rollouts, leadership assessment data is only useful when it joins the rest of the workforce data. A Hogan report that lives in a coaching folder and never connects to the skills inventory does not help the board answer "do we have the leadership capability to deliver this strategy."
This is where leadership assessment intersects with workforce skill intelligence. HackerEarth's SkillsMap benchmarks workforce capability across 1,000+ skills using 150M+ assessment signals — including leadership and managerial competencies — so that individual assessment data rolls up into a defensible workforce view. For organizations running AI-readiness or skills-based hiring programs, that aggregation turns scattered assessment reports into strategic input.
For technical leadership specifically — engineering managers, staff-plus engineers moving into management — leadership instruments alone underweight the technical-judgment dimension. Pair a leadership assessment with a structured technical evaluation using a skills assessment platform calibrated to the role's actual demands.
Common pitfalls to avoid with leadership assessment tests
A few patterns worth flagging:
- Using personality assessments as selection tools without local validation. Most vendors will sell you the instrument; few will help you build the validity study that makes it defensible under audit. For BFSI and regulated industries especially, an un-validated assessment is a litigation risk, not an asset.
- Skipping the debrief. Reports without conversations are wasted budget. A Hogan report is worth more in a 90-minute debrief than three reports without one.
- Treating assessments as one-shot events. The value compounds when you re-assess. We recommend treating a 360 done once as information, and a 360 done annually as a development arc.
- Confusing popularity with validity. MBTI is the most popular instrument on this list and the least defensible for high-stakes decisions. Popularity is not evidence.
Frequently asked questions about leadership assessment tests
Are leadership assessment tests legally defensible? Leadership assessment tests can be legally defensible when they are job-related, locally validated against the role, and applied consistently across candidates. In the United States, the EEOC's Uniform Guidelines on Employee Selection Procedures set the standard. Un-validated, off-the-shelf assessments used in high-stakes selection are the most common source of litigation risk.
How many leadership assessment tests should you use per hire? A common approach is no more than two instruments per decision — typically one personality or derailer-focused assessment paired with a 360 or structured interview. Stacking three or more rarely improves predictive accuracy and adds report fatigue.
What is the difference between a personality assessment and a leadership assessment test? A personality assessment measures stable traits (e.g., Hogan HPI, MBTI). A leadership assessment test evaluates leadership-relevant behaviors, judgment, or outcomes — often by applying a personality instrument plus multi-rater feedback, situational judgment, or simulation data to a leadership context. All leadership assessments draw on personality data; not all personality assessments are leadership assessments.
Which leadership assessment test is most accurate? Accuracy depends on the decision. For senior selection and succession, Hogan paired with a validated 360 is widely considered among the most defensible combinations. For mid-manager development, the LPI is well-evidenced. No single test is "most accurate" across all use cases.
How long does a leadership assessment test take? Administration time varies. DISC and MBTI typically take 15–30 minutes. CliftonStrengths takes around 30–45 minutes. The EQ-i 2.0 takes roughly 20–30 minutes. A full Hogan battery typically requires two to three hours plus a debrief. A 360 process usually spans two to four weeks end-to-end, depending on rater response time.
Conclusion
Leadership assessment in 2026 is less about picking the perfect instrument and more about building a tiered, defensible system: heavyweight assessments for senior decisions, lighter tools for development, and an aggregation layer that connects individual data to workforce-level capability. The seven leadership assessment tests covered here address most of what enterprises need. The trick is using them where they earn their cost and not using them where they don't.
If your current leadership program is built on one assessment used for everything from first-line manager development to C-suite succession, you are over-relying on the instrument and under-investing in the surrounding process. The fix is rarely a different test. It is a better system.
Next steps
See how SkillsMap connects individual assessment data to workforce-level capability — explore HackerEarth's skills intelligence platform or talk to our team about leadership skill benchmarking.