



The prevailing architecture of technical recruitment in the modern corporate environment often rests upon a surprisingly fragile foundation of intuition and unstructured conversation. Despite the significant financial and operational stakes associated with engineering hires, many organizations continue to rely on a process where different interviewers ask disparate questions, evaluate candidates based on subjective impressions, and reach conclusions fueled by internal heuristics rather than objective data. This systemic inconsistency represents a primary drain on engineering resources, as it leads to high variability in hire quality, increased time-to-hire, and the unchecked proliferation of unconscious bias. The solution to this diagnostic failure lies in the rigorous implementation of a structured interview process, a methodology supported by over eighty-five years of industrial-organizational psychology research. By transforming the interview from a casual dialogue into a standardized assessment, firms can achieve a level of predictive validity that is unattainable through traditional means.
The definition and core components of structured interviewing
A structured interview is fundamentally distinct from the common practice of simply having a prepared list of questions. It is a systematic employment assessment approach where every component of the candidate evaluation is kept entirely consistent. To qualify as a truly structured process, an interview must adhere to three non-negotiable pillars: the use of predetermined, job-relevant questions; a consistent delivery process for all candidates; and the application of standardized evaluation criteria. If any of these elements are absent, the process reverts to a state of semi-structured or unstructured evaluation, significantly diluting the predictive accuracy of the hire.
The first pillar, predetermined questions, requires that every candidate for a specific role encounters the exact same queries in the same sequence. This eliminates the variable of interviewer influence on the conversational flow, ensuring that the differences in candidate responses reflect differences in their actual abilities rather than differences in the questions asked. The second pillar involves a consistent process, which encompasses the interview length, the number of interviewers, and the format (whether remote, in-person, or hybrid). The third pillar, standardized evaluation, is perhaps the most frequently overlooked. It necessitates the use of a formal scoring system, such as a rubric or scorecard, created alongside the job description to evaluate every candidate against the same "rulebook".
The taxonomy of interview formats and hiring outcomes
In technical hiring, interviews exist on a spectrum ranging from entirely ad-hoc to fully standardized. Understanding where an organization currently lands on this spectrum is the first step toward optimization. Research indicates that the move from unstructured to structured formats is not a marginal improvement but a doubling of the tool's effectiveness.
The failure of unstructured interviews
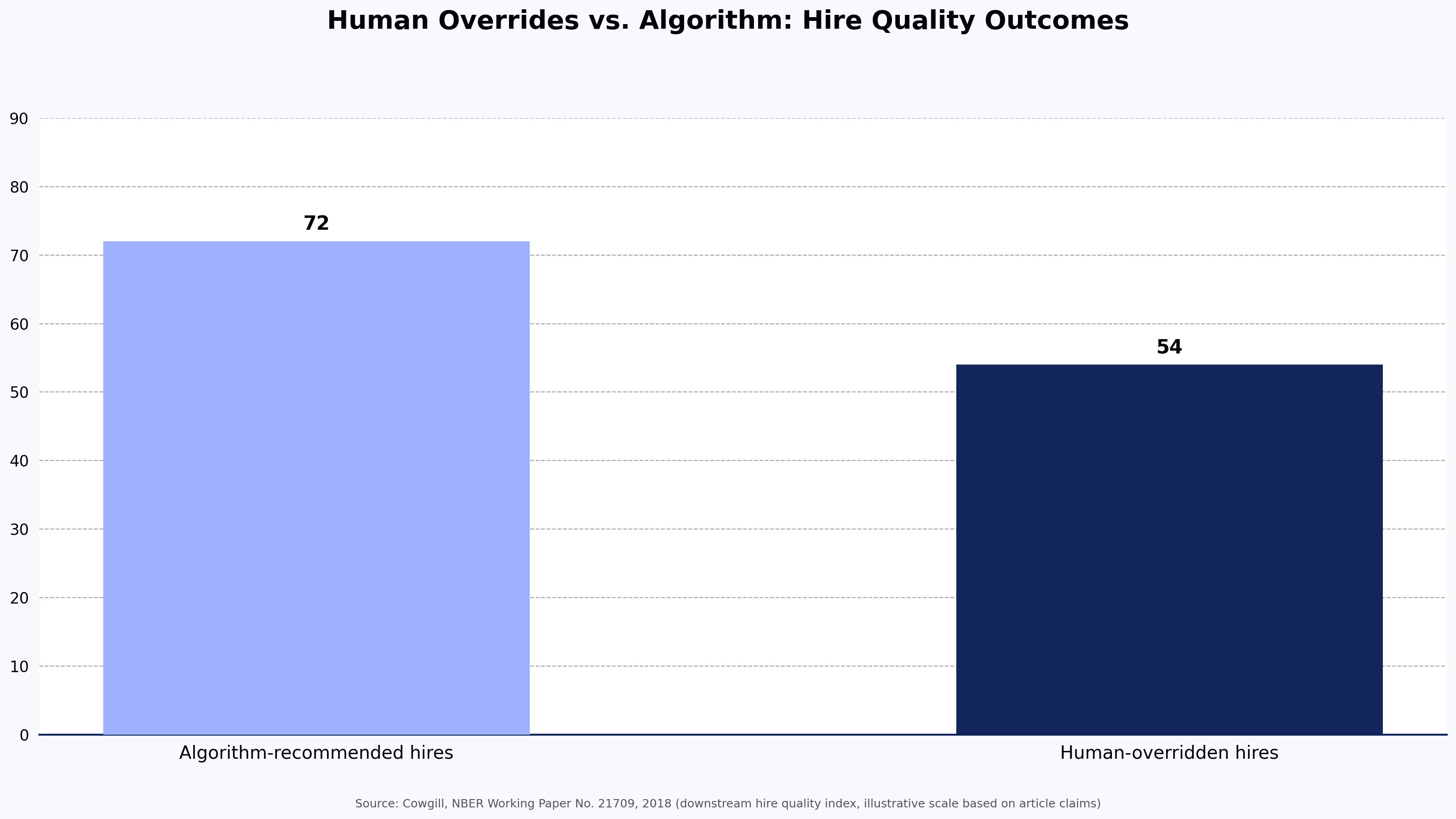
Unstructured interviews, characterized by an informal or casual tone, involve hiring managers asking unplanned questions based on a candidate’s skills or even personal interests. While this format feels natural and allows for a sense of "personal connection," it is objectively the least reliable method of selection. The validity coefficient of an unstructured interview is approximately 0.20, meaning it explains only about 4% of the variance in actual job performance. This is barely superior to a random selection process and leaves the organization vulnerable to legal challenges because there is no documented, consistent process to defend.
The ambiguity of semi-structured interviews
The semi-structured or "hybrid" format is common in mid-sized tech companies. It involves preparing some questions in advance but allows the interviewer to go "off-script" to explore various topics. While this offers more flexibility, it still lacks the objectivity of a fully structured approach. The danger of the semi-structured format lies in the "last mile" of evaluation; when interviewers deviate from the script, they often introduce bias through leading questions or by over-weighting information that is irrelevant to the job requirements.
The predictive power of structured interviews
Structured interviews reach a validity coefficient of 0.51, explaining roughly 26% of the variance in job performance. This makes them one of the best predictors of success available to hiring teams, particularly when combined with General Mental Ability (GMA) tests. Interestingly, a single structured interview has been shown to yield the same level of validity in predicting job performance as three or four unstructured interviews, representing a massive efficiency gain for engineering teams whose time is a premium resource.
The science of structured interviews: bias and prediction
The transition to a structured process is not merely an administrative preference; it is a psychological intervention designed to counteract the flaws of human cognition. The human brain is naturally inclined toward heuristics that simplify decision-making but often lead to erroneous conclusions in a professional context.
Cognitive bias reduction
Unconscious bias remains a significant barrier to effective technical hiring. Without a structured framework, interviewers are susceptible to several documented biases. Affinity bias, for instance, leads interviewers to favor candidates who remind them of themselves or share common hobbies, regardless of skill level. The halo effect occurs when an interviewer allows one positive trait—such as a candidate having attended a prestigious university—to color the entire assessment. Confirmation bias drives interviewers to spend the session seeking out information that confirms their first impression, which is usually formed within the first thirty seconds.
Structured interviews mitigate these biases by forcing the focus onto job-relevant criteria. By requiring every candidate to answer the same questions and assessing those answers against a fixed rubric, the process reduces the "noise" created by personal impressions. Research demonstrates that structured interviews can slash bias by up to 85% compared to unstructured methods.
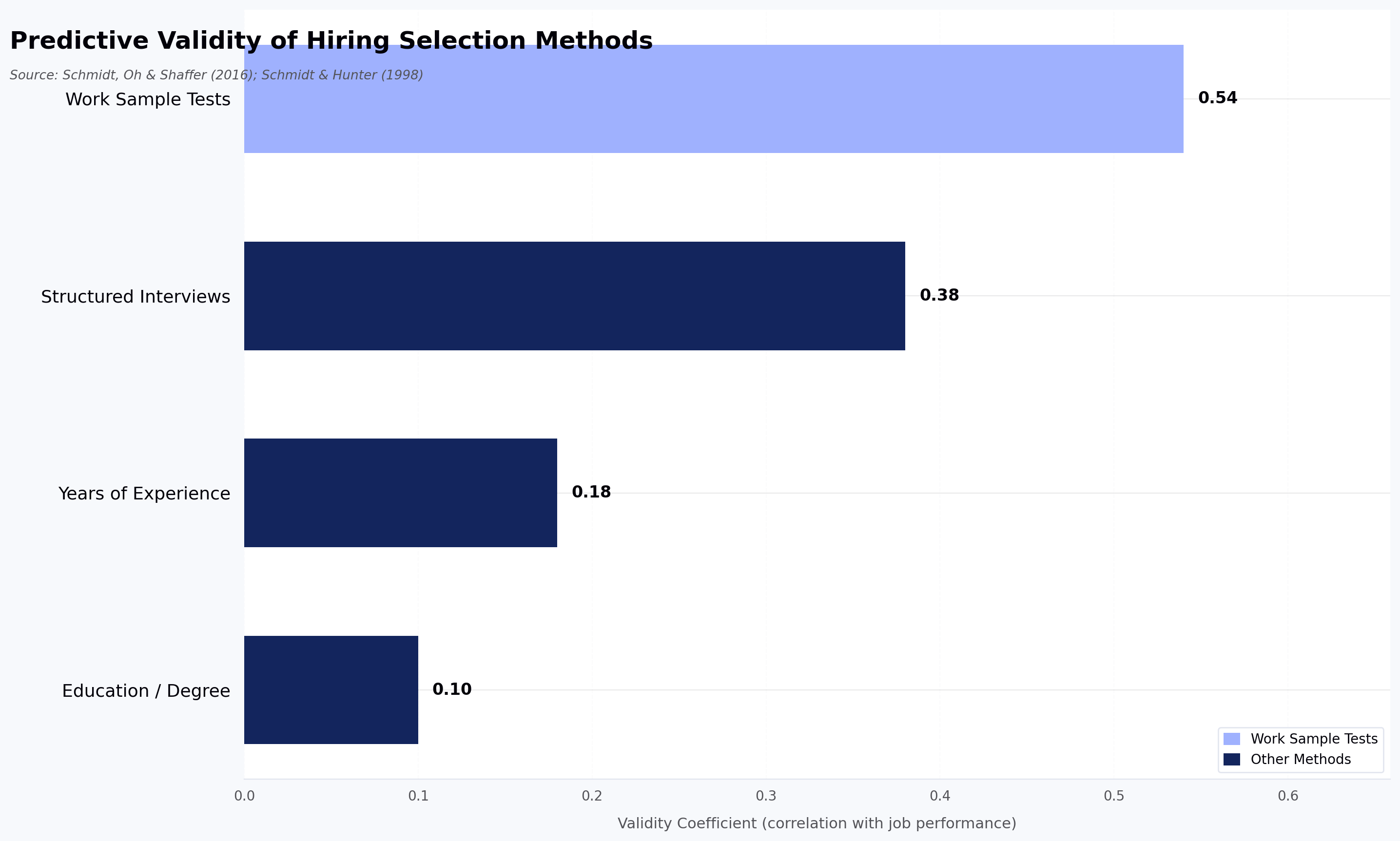
Predictive validity and general mental ability
The work of Schmidt and Hunter is foundational to understanding the predictive power of selection tools. Their meta-analysis of eighty-five years of research identified that General Mental Ability (GMA) is the primary predictor of performance in all types of jobs.6 However, the combination of a GMA test and a structured interview reaches a composite validity of 0.63, providing a highly accurate view of a candidate's future potential. For technical roles, where both cognitive ability and specific behavioral competencies are required, this combination is the most defensible and effective strategy for minimizing "bad hires".
Candidate perception and legal defense
A common misconception is that candidates dislike the rigidity of structured interviews. On the contrary, research suggests that candidates are up to 35% more likely to perceive the process as fair, even when they are rejected, if the process is consistent and standardized. This perception of fairness directly impacts an organization’s employer brand and offer acceptance rates. From a legal standpoint, the lack of objectivity in unstructured interviews makes them vulnerable to discrimination claims. A structured process, which relies on documented job analysis and consistent scoring, provides the legal defensibility required by enterprise-level organizations.
Step 1: conduct a job analysis and define success criteria
The architecture of a successful interview process must be built before a single candidate is met. The most common mistake hiring managers make is jumping directly to question design without first understanding the fundamental requirements of the role. This foundational step involves a deep dive into the specific competencies that drive success within the organization's unique environment.
Identifying core competencies
Hiring teams must move beyond generic job descriptions to identify the 5 to 8 core competencies that truly define success in the role. This is best achieved by analyzing actual job tasks and interviewing top performers to determine what behaviors lead to excellence versus those that lead to struggle. For a software engineer, these competencies often include a mix of technical scope, problem-solving, ownership, and collaboration.
Defining the engineering ladder
Success criteria should be mapped to the specific level of the role, as expectations for a junior engineer differ significantly from those of a principal architect. A structured skill matrix helps by mapping observable behaviors to each level of the engineering ladder.
This level of specificity ensures that the evaluation is grounded in the actual needs of the team, preventing the common pitfall of hiring for "general talent" that may not fit the specific requirements of the current project horizon.
Step 2: design job-relevant interview questions
The effectiveness of a structured interview rests on the "mapping principle": every question must tie directly back to a competency identified in the job analysis phase. If a question cannot be clearly linked to a success criterion, it should be removed from the process.
Categories of structured questions
There are four primary types of questions used in a structured technical interview, each serving a distinct diagnostic purpose.
- Behavioral questions: These ask candidates to describe past actions (e.g., "Tell me about a time you had to explain something complex to a non-technical stakeholder"). They are based on the premise that past behavior is the best predictor of future behavior.
- Situational (hypothetical) questions: These present a hypothetical scenario to assess judgment (e.g., "What would you do if you were assigned multiple projects with conflicting tight deadlines?").
- Job knowledge questions: These assess domain-specific expertise (e.g., "What are the differences between SQL and NoSQL databases?").
- Problem-solving/technical questions: These assess analytical approach and technical proficiency through coding challenges or system design discussions.
Anatomy of a high-quality question
A good question is specific enough to elicit detailed responses but open enough to allow for different valid approaches. It should encourage the candidate to use the STAR (Situation, Task, Action, Result) format to provide a comprehensive answer. For example, instead of asking, "Are you good at debugging?" a structured question would be: "Describe a difficult bug you were tasked with fixing in a large application. How did you identify the root cause, and what was the final result?".
Crucially, follow-up questions must also be predetermined. Going off-script with spontaneous probing is where bias often re-enters the conversation. Pre-written prompts such as "What was the biggest challenge in that situation?" or "How did your actions impact the team?" ensure that every candidate is pushed to the same level of depth.
Step 3: Create a standardized scoring rubric
Standardized questions are only half of the solution; without a consistent way to evaluate the answers, the process remains subjective. The gold standard for evaluation is the Behaviorally Anchored Rating Scale (BARS), which links numerical ratings to specific, observable behaviors.
The mechanics of bars
Unlike vague scales (e.g., 1 = poor, 5 = excellent), a BARS provides descriptors for what each score looks like for a specific competency. This eliminates the "rater drift" that occurs when two interviewers interpret an "average" performance differently.
Weighting and knockouts
Not all competencies are equal. For some roles, technical depth may be weighted more heavily than leadership potential. The rubric should reflect these priorities, ensuring that the final score aligns with the most critical requirements of the role. Additionally, clear "knockout" criteria should be established for non-negotiable standards, such as ethical dilemmas or fundamental technical gaps.
Step 4: train your interviewers
The human element is the most significant variable in the interview process. Even the most perfect questions and rubrics will fail if the interviewers are not trained to deliver them correctly. Training is not just about compliance; it is about building interviewer confidence and reducing the perceived burden of the process.
Addressing interviewer resistance
Many experienced engineers feel that structure is too robotic or that it implies their professional judgment is not trusted. Training must address this by framing structure as a tool that amplifies their expertise. When interviewers don't have to worry about what to ask next, they can focus entirely on active listening and evaluating the candidate's responses against the rubric.
Calibration exercises
Calibration is the process of ensuring that different interviewers apply the rubric in the same way. Recommended exercises include:
- Shadowing: New interviewers observe experienced ones to learn the rhythm of a structured interview.
- Reverse shadowing: A veteran observes a new interviewer and provides feedback on their delivery and note-taking.
- Mock scoring: The team watches a recorded interview and scores it individually, then discusses their ratings to align on the standards for a "3" versus a "4".
Regular calibration prevents "rater inflation" and ensures that the hiring bar remains consistent across different teams and departments.
Step 5: standardize the interview day experience
Candidate experience is a critical, yet often overlooked, part of structured interviewing. A chaotic or inconsistent process damages an organization's employer brand and can lead to top talent dropping out of the pipeline.
The ideal interview flow
Every candidate for a specific role should experience the same timeline and agenda. This prevents fatigue or "warm-up" advantages from skewing the results.
Panel coordination
In panel interviews, it is essential to divide the focus areas beforehand. One interviewer may be assigned to assess technical proficiency, while another focuses on collaboration and communication. This prevents the interview from feeling like an interrogation and ensures that all core competencies are covered without unnecessary duplication.
Step 6: evaluate candidates using evidence, not gut feeling
The decision-making process after the interview is where bias most commonly re-enters the system. Many teams do excellent work in the interview itself, only to make the final choice based on who they "liked" most in the debrief room.
Independent scoring first
To prevent groupthink and anchoring, every interviewer must complete their individual scorecard before any group discussion occurs. This ensures that each person's perspective is based solely on their interaction with the candidate, rather than being swayed by the opinions of more senior colleagues.
Evidence-based debriefs
The debrief meeting should be a structured review of the data, not a casual discussion of impressions. Each interviewer should share their scores and provide specific evidence—actual things the candidate said or did—to support those ratings. For example, instead of saying, "They seemed smart," an interviewer should say, "They demonstrated high problem-solving ability by breaking down the system design into three modular components and explaining the trade-offs of each".
If there is a disagreement in scores, the facilitator should ask, "What specific observation led to that rating?" This keeps the conversation focused on objective data and helps the team identify if one interviewer missed a key detail or if another was influenced by an unconscious bias.
Common mistakes that undermine structured Interviews
Even with a well-intentioned process, organizational habits can erode the benefits of structure. Recognizing these pitfalls is essential for long-term success.
- Going off-script with follow-ups: The temptation to probe with unplanned questions is high, but it reintroduces variability. All probing questions should be pre-set in the interview kit.
- Failing to retrain: Interviewer habits naturally drift over time. Organizations need regular "refresher" calibration sessions to keep the team aligned.
- Using generic question banks: A question that works for a Product Manager may not work for a DevOps Engineer. Questions must be mapped to role-specific competencies.
- Discussing candidates in the "hallway": Casual comments before individual scoring is complete can anchor opinions and undermine the independence of the evaluation.
- Treating culture fit as a vibe: "Culture fit" is often a mask for affinity bias. It should be replaced with "culture add," assessed through specific behavioral questions tied to company values.
How to measure structured interview effectiveness
Without measurement, an organization cannot know if its structured process is actually delivering better results. Structured interviews generate consistent data, which enables continuous improvement through several key metrics.
Quality of hire (qoh)
Quality of Hire is the ultimate test of any recruitment process. It measures the value a new hire brings to the organization compared to pre-hire expectations. This is calculated by correlating interview scores with post-hire performance data, such as first-year performance reviews, ramp-up time, and retention rates.
Time-to-hire and efficiency
While building a structured process takes more time upfront, it often reduces the overall time-to-hire by speeding up the decision-making phase. Teams should track how long it takes from the initial interview to the final offer. Additionally, monitoring "interviewer load" helps prevent burnout among top engineers.
Pipeline diversity
A primary benefit of structure is the reduction of bias, which should manifest in a more diverse candidate pipeline at the offer stage. Tracking whether underrepresented candidates are being evaluated fairly based on the same rubric as their peers is a crucial metric for modern talent teams.
How technology can scale structured interviewing
For enterprise-level tech companies, the manual execution of structured interviews at high volume is often the biggest bottleneck in the hiring process. Technology serves as the "human amplifier," ensuring the methodology is followed without draining engineering resources.
challenges of manual scaling
Every structured interview requires significant time from trained engineers and recruiters. Coordinating schedules, ensuring consistency across hundreds of interviewers, and managing the documentation burden often leads to "process decay," where the team reverts to unstructured habits to save time.
The role of automation
Modern technical assessment platforms, such as HackerEarth, address these scaling challenges by automating the delivery and evaluation of the interview. Standardized delivery platforms ensure every candidate gets identical questions, while AI-powered screening handles the initial evaluation at scale, identifying the top 20% of candidates in minutes rather than weeks.
Automated scheduling removes the coordination friction that often delays the process, and built-in recording and transcript features ensure that the evidence is captured accurately for the final debrief. Technology doesn't replace the structured methodology; it makes it executable at the speed of a high-growth tech business.
Automate structured interviews with hackerearth
HackerEarth’s suite of tools is designed to help engineering leaders implement a structured interview process with precision and efficiency.
AI interview agent
The AI Interview Agent is the world’s most advanced technical interviewer, capable of conducting end-to-end technical and behavioral interviews without bottlenecks.
- Expert technical knowledge: Backed by a library of 25,000+ curated questions, it evaluates depth across 30+ programming languages and complex system design.
- Bias elimination: The agent masks personal information and uses standardized rubrics to achieve near-zero unconscious bias in the evaluation process.
- Adaptive questioning: It uses candidate responses to shape follow-up questions, creating a natural flow that ensures candidates are neither over-challenged nor under-tested.
Facecode for live interviews
When human intervention is needed for the final rounds, FaceCode provides an intelligent live coding platform that supports structured evaluation. It features collaborative code editing, PII masking, and AI-powered interview summaries that highlight not just technical performance but also behavioral insights like communication clarity and problem-solving approach.
By leveraging these technologies, organizations can move from an ad-hoc hiring culture to a scalable, data-driven engine that consistently identifies and attracts the best technical talent in the world. The structured interview is not just a better way to hire; it is a competitive advantage in the race for engineering excellence.