Meta title: Cybersecurity interview questions to ask candidates Meta description: A practitioner's guide to cybersecurity interview questions for recruiters and engineering managers — with evaluative criteria, model answer signals, and FAQs. Read time: 8 min read Primary keyword: cybersecurity interview questions Last reviewed: 2024
Interview questions to ask cybersecurity candidates
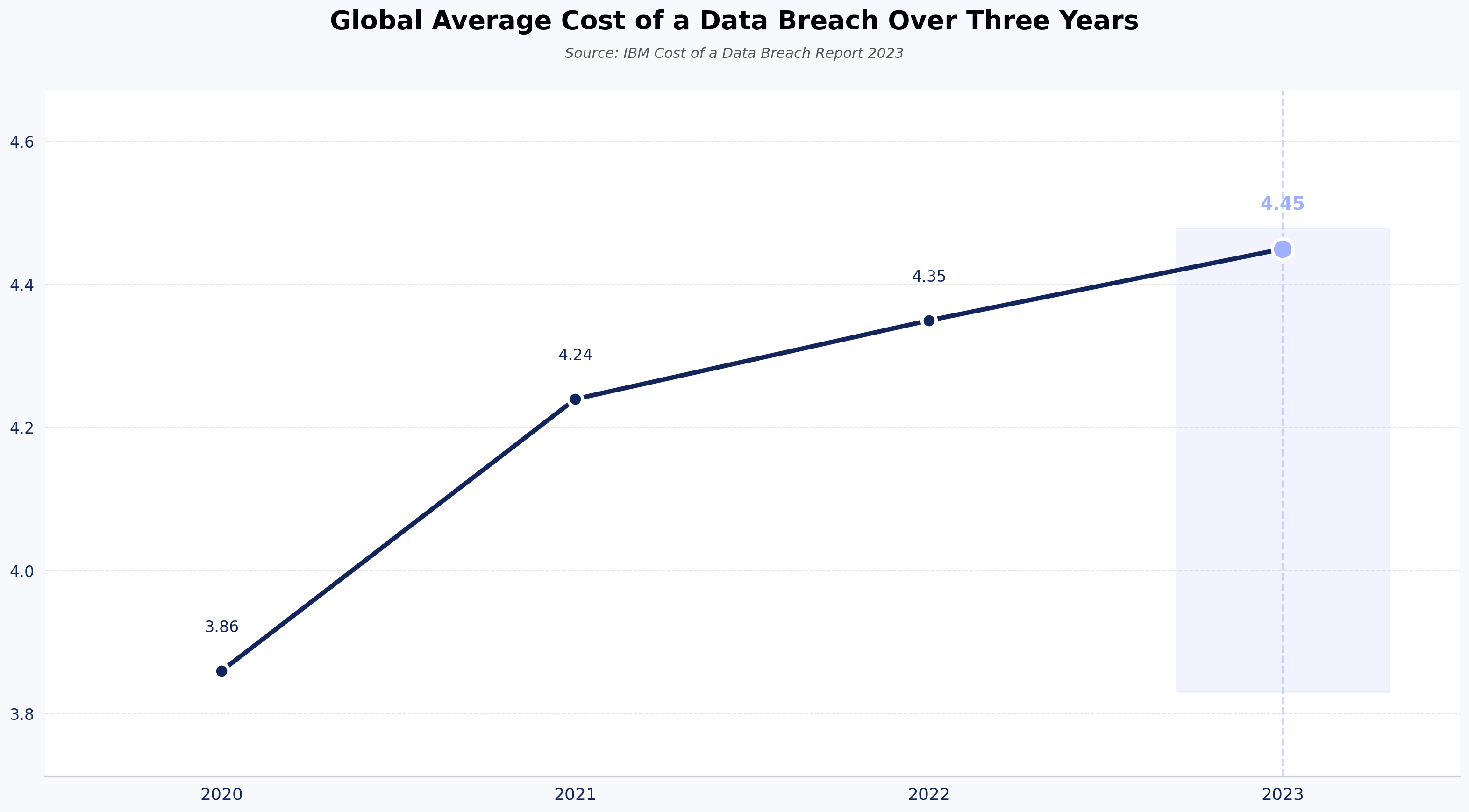
Cybersecurity interview questions should test whether a candidate can triage a live threat, not just recite frameworks. According to the IBM Cost of a Data Breach Report 2023, the global average cost of a data breach reached USD 4.45 million — a 15% increase over three years (figures as of 2023; check IBM for the latest edition). That makes the quality of your security hires a direct business risk.
This guide is written primarily for technical recruiters screening cybersecurity candidates, with secondary depth for engineering managers and security leads running the technical panel. Recruiters can use the "What to look for" cues to calibrate phone screens; hiring managers can use the question groupings to structure deeper panels. It covers security operations, threat detection, penetration testing, and incident response — along with what a strong answer looks like for each.
Use these questions to evaluate candidates for roles like SOC analyst, security engineer, or penetration tester. Calibrate depth to seniority: a junior SOC analyst should demonstrate solid fundamentals and tooling literacy, while a senior engineer or security lead should show judgment, incident command experience, and the ability to translate risk to non-technical stakeholders.
Our take: Certifications like CISSP, CEH, CompTIA Security+, and OSCP signal baseline knowledge, but they matter less than a candidate's ability to demonstrate live threat triage under pressure. Consider allocating at least 30–40% of total evaluation weight to practical, scenario-based tasks rather than question-and-answer rounds alone.
Why a thorough technical interview matters for cybersecurity hires
Resumes and certifications can tell you what a candidate has studied; they rarely tell you how they will respond when an alert fires at 2 a.m. A structured cybersecurity interview gives you a controlled environment to test reasoning, communication, and triage skills before a hire ever touches your production environment.
To structure the interview itself, plan a 45–60 minute panel with three segments: 10–15 minutes on fundamentals (definitions, tooling literacy), 20–25 minutes on scenario-based reasoning (walk-throughs of past incidents or hypothetical attacks), and 10–15 minutes on collaboration and communication (cross-functional examples, executive-facing framing). Assign one interviewer to lead each segment so the candidate isn't whiplashed between topics, and reserve the last five minutes for the candidate's own questions — what they ask often reveals more than how they answer.
Pairing structured cybersecurity interview questions with a practical skills assessment narrows the gap between resume claims and on-the-job behavior. HackerEarth's technical assessments let you evaluate candidates against role-specific technical tasks — including scenario-based exercises like log review or configuration audits — so interviewers can spend their time probing judgment rather than verifying basics.
For live interviews, FaceCode helps when you need to run a panel with multiple interviewers without losing structure: it supports panel interviews with multiple interviewers, a code editor with auto-evaluation, and direct access to HackerEarth's question library during the session.
Top cybersecurity interview questions to ask candidates
The questions below are grouped into four themes: fundamentals and credentials, threat detection and response, practical defense and tooling, and collaboration and communication. Use the grouping to plan a 45–60 minute panel — pick two or three from each group based on the role's seniority. For role-specific framing, see our related guide on hiring developer talent: SQL interview questions for an example of how to structure technical question sets by seniority.
Fundamentals and credentials
State your personal achievements and certifications in cybersecurity
A strong opener establishes whether the candidate's formal credentials (CISSP, CEH, CompTIA Security+, OSCP, GIAC) match the work they've actually done. Ask the candidate to walk through one certification and one project that reinforced it.
What to look for: Candidates who can connect a credential to a concrete outcome — for example, applying OSCP techniques during an internal red-team exercise. Be cautious of certification stacks with no applied story behind them.
What is effective cybersecurity, and how would you quantify it?
There's no single correct answer; the value of this question lies in seeing how the candidate defines and measures effectiveness. Strong candidates reach for metrics like mean time to detect (MTTD), mean time to respond (MTTR), patch latency, or coverage of the MITRE ATT&CK matrix.
What to look for: Specific, measurable parameters and an awareness that "effective" depends on the organization's risk profile. Avoid candidates who default to vague filler like "industry-standard" without definitions.
Are cybersecurity certifications the most important factor in this field?
This is a values question disguised as a knowledge question. Many hiring managers find that practical experience is weighted heavily alongside certifications, particularly for incident response and offensive security roles.
What to look for: Candidates who articulate a balanced view — certifications validate baseline knowledge, but applied experience signals how someone behaves during a real incident.
Threat detection and response
If you were a hacker, how would you steal our information?
A good answer reasons through reconnaissance, initial access, and lateral movement against a generic target — since the candidate doesn't know your environment, the goal is to surface adversarial thinking, not insider knowledge.
What to look for: Structured thinking that maps to a recognized framework (e.g., the cyber kill chain or MITRE ATT&CK), and the ability to articulate plausible attack paths rather than movie-style scenarios.
Tell us about a time when you resolved a vulnerability in your company's server
Past behavior is the strongest available predictor of future behavior in incident response. Probe for the timeline: how was the vulnerability discovered, who was notified, what was the remediation, and what changed afterward?
What to look for: A clear narrative of detection, triage, containment, and post-incident review. Bonus signal: candidates who mention root-cause analysis or process changes they drove as a result.
Have you ever identified an incoming cyberattack? How did you handle it?
A strong answer describes a specific incident with named tooling, a validation step, and an escalation path — generic "we saw an alert and responded" answers indicate shallow experience.
What to look for: Specific tooling references (SIEM platforms, EDR/XDR tools, IDS/IPS), and an explicit description of how the candidate distinguished signal from noise.
What is the difference between IDS and IPS?
A strong answer: an IDS (Intrusion Detection System) monitors network or system activity and alerts on suspicious behavior, but does not block it. An IPS (Intrusion Prevention System) also detects suspicious activity and actively blocks or prevents it inline. The key distinction is active prevention — IPS sits in the traffic path and can drop packets; IDS observes out-of-band.
What to look for: A candidate who clearly names active prevention as the distinguishing capability of IPS, and who can discuss trade-offs (false positives blocking legitimate traffic, placement in network topology).
Explain active reconnaissance
Active reconnaissance is the pre-attack phase in which an attacker directly interacts with a target system to gather information — for example, port scanning, ping sweeps, banner grabbing, or vulnerability scanning. Because it generates traffic the target can observe, active recon is detectable by IDS/IPS and log analysis, in contrast to passive recon (open-source intelligence, DNS lookups).
What to look for: Correct framing as an information-gathering phase rather than data theft, plus examples of tools (Nmap, Nessus) and the detection signatures they typically produce.
What are polymorphic viruses?
Polymorphic viruses change their code or signature each time they propagate or infect a new file, while preserving the underlying malicious payload. This defeats signature-based detection and requires behavior-based or heuristic approaches.
What to look for: Candidates who connect polymorphism to detection strategy — sandboxing, behavioral analytics, EDR — rather than just defining the term.
Practical defense and tooling
When building firewalls, do you choose closed ports or filtered ports? Explain why
Filtered ports drop packets silently and reveal less to a scanner, while closed ports actively respond with a TCP RST. Most defensive postures prefer filtered for external-facing perimeters because they slow down reconnaissance.
What to look for: Reasoning grounded in the threat model — perimeter vs. internal segmentation, scanner behavior, and the operational cost of debugging dropped traffic.
How will you prevent a brute-force attack?
A strong answer covers multiple layers: account lockout policies, rate limiting, CAPTCHA, multi-factor authentication, monitoring for distributed attempts (credential stuffing), and using password hashing with adaptive functions like bcrypt or Argon2.
What to look for: Defense-in-depth thinking. Single-control answers (e.g., "just enable MFA") are weaker than layered responses.
Explain system hardening
System hardening reduces a system's attack surface by disabling unused services and ports, applying least-privilege configurations, patching, enforcing secure baselines (e.g., CIS benchmarks), and removing default credentials.
What to look for: A practical example from the candidate's own work — what they hardened, the baseline they applied, and the residual risk they accepted.
What is in your home network?
A candidate's home setup can reveal tooling literacy and genuine curiosity — but treat this as a bonus signal, not a gate. Many strong candidates, especially career-changers or those without disposable income for hardware, won't have a home lab. Use this question to learn about hands-on interest where it exists, not to penalize its absence.
What to look for: How the candidate uses what they have — segmentation, monitoring, experimentation, or even cloud-based labs and CTF participation — rather than the price tag of the equipment. If a candidate has no home lab, ask about sandboxed environments they've used at work or in training instead.
Do you have an emergency procedure in place?
Probe whether the candidate has built or operated under an incident response plan. Reference frameworks: NIST SP 800-61, SANS PICERL.
What to look for: Familiarity with runbooks, on-call structures, communication trees, and tabletop exercises. Bonus: candidates who mention post-incident review as part of the procedure.
Collaboration and communication
If there was a major security breach, how would you inform your superiors?
A strong answer distinguishes between technical detail for the security team and business impact framing for executives — the same incident requires two different communications.
What to look for: Ability to translate technical severity into business terms — affected systems, data exposure, regulatory implications, and a clear ask for decisions.
Tell us about how you work with a team, and give an example
Security work is rarely solo. Candidates need to collaborate with IT, engineering, legal, and compliance.
What to look for: Specific examples of cross-functional work — a remediation that required engineering buy-in, a policy change negotiated with legal. Watch for hesitation, which can indicate limited team experience.
What do you think is this organization's cybersecurity risk?
A candidate shouldn't be able to answer this accurately without information — and that's the point. The right move is to ask clarifying questions about industry, regulatory exposure, tech stack, and current controls.
What to look for: Candidates who probe before prescribing. Candidates who offer a one-size-fits-all answer reveal a checklist mindset rather than a risk-based one.
If you were our cybersecurity expert, what would you need from us to do the job?
This surfaces realism about budget, headcount, tooling, and executive sponsorship.
What to look for: Reasonable, prioritized asks — not just a wish list of tools. Strong candidates name organizational enablers (executive sponsorship, change-management authority) alongside technical tooling.
Have you ever taken down your company's network during testing?
Honesty signal. Candidates who admit to a mistake and describe what they learned demonstrate the kind of accountability you want during a real incident.
What to look for: A candid account, the recovery steps, and the controls or guardrails the candidate put in place afterward (change windows, blast-radius limits, staging environments).
How would you strengthen our company's cyber defense?
A closing question that tests synthesis. Strong candidates won't answer immediately — they'll outline what they'd need to assess first (asset inventory, current controls, recent incidents) before proposing changes.
What to look for: A diagnostic mindset over a prescriptive one. Candidates who lead with "it depends on what I find in the first 30 days" usually outperform those who name specific products without context.
When these questions are not enough
Even the best question set has blind spots. A few worth flagging before you finalize your panel:
- Recall is not capability. A candidate can define polymorphic viruses without being able to triage one in a packet capture. Pair questions with a hands-on, scenario-based exercise — log review, configuration audit, or a capture-the-flag style task.
- Frameworks are not judgment. Naming MITRE ATT&CK tactics is easier than applying them under time pressure.
- Some questions can disadvantage candidates unfairly. Home-lab questions, for instance, assume disposable income for hardware and quiet time outside work — both of which correlate with privilege rather than capability. If you ask them, treat the answers as bonus signal, not baseline.
- Rehearsal effect is real. Common cybersecurity interview questions circulate on prep sites; conversational fluency on familiar prompts does not predict performance on novel ones.
Key takeaways
- Calibrate cybersecurity interview questions to seniority — a SOC analyst panel differs from a security lead panel.
- Name specific credentials (CISSP, CEH, CompTIA Security+, OSCP) when asking about certifications, and weight applied experience alongside them.
- Group questions into fundamentals, threat detection, defense and tooling, and collaboration to cover the full role.
- During the interview, correct factual errors in real time — IDS detects and alerts; IPS detects and actively blocks inline.
- Pair interviews with a practical assessment to control for rehearsed answers, and watch for questions (like home-lab setups) that can unfairly disadvantage some candidates.
FAQs
What are the most common cybersecurity interview questions?
The most-asked questions in real panels cluster around three areas, but a counterintuitive note: the questions candidates rehearse most (IDS vs. IPS, define system hardening) are the weakest discriminators. Stronger panels weight scenario walk-throughs ("describe an alert you investigated last quarter") and tool-specific probes ("what query language does your current SIEM use?") because these are harder to memorize from prep sites. Use definitional questions as warm-ups, not as the basis for your hire/no-hire decision.
How do you interview a cybersecurity analyst?
Interview a cybersecurity analyst by combining technical fundamentals (network protocols, common attack vectors, SIEM tooling), scenario-based reasoning (walk through a suspicious alert), and behavioral questions about prior incidents. For junior analysts, weight fundamentals and tooling literacy; for senior analysts, weight judgment, communication, and incident command experience.
What certifications should a cybersecurity candidate have?
Common cybersecurity certifications include CompTIA Security+ for entry-level roles, CEH and GIAC certifications for mid-level practitioners, CISSP for senior and management-track candidates, and OSCP for offensive security and penetration testing roles. Treat certifications as evidence of baseline knowledge, not as a substitute for applied experience.
How long should a cybersecurity interview loop run end-to-end?
A single panel runs 45–60 minutes, but the full loop — phone screen, technical panel, practical assessment, and a final cross-functional or leadership round — typically spans 4–6 hours of candidate time across one to two weeks. If your loop is shorter than three hours total, you're likely under-assessing; if it exceeds eight hours, you'll see drop-off from strong candidates with competing offers.
What's the difference between IDS and IPS in a cybersecurity interview?
An IDS (Intrusion Detection System) monitors traffic or system activity and generates alerts on suspicious behavior, but it does not block traffic. An IPS (Intrusion Prevention System) sits inline, detects suspicious activity, and actively blocks or prevents it. The defining capability of an IPS is active prevention.
Can interview questions alone identify a strong cybersecurity hire?
No. Interview questions test reasoning and communication but cannot reliably measure hands-on capability — candidates can rehearse answers, and conversational fluency does not always predict performance under pressure. Pair cybersecurity interview questions with a practical, scenario-based skills assessment.
Next steps
Ready to move beyond rehearsed answers? Explore HackerEarth's technical assessments to evaluate candidates against role-specific technical tasks before they reach your interview panel — or book a demo of FaceCode to see how panel interviews with live code evaluation work in practice.
Also read: Hiring DEV Talent: SQL Interview Questions