AI is not replacing developers — it is redefining how code gets created. A growing wave of software professionals now describe what they want in plain English and let AI generate the code. This approach has a name: vibe coding.
Since the term was coined in early 2025, vibe coding has gone from a niche Twitter concept to a mainstream development methodology. A 2025 GitHub survey found that 92% of developers now use AI coding tools in some capacity, and roughly 46% of new code in enterprise environments is AI-generated. Whether you are an experienced engineer, a product manager prototyping an idea, or a recruiter evaluating technical talent, understanding vibe coding is no longer optional.
This guide breaks down what vibe coding means, how it works, the tools driving it, and where it is headed — including its direct impact on developer hiring and technical skills assessment.
What Is Vibe Coding? (Definition & Meaning)
Vibe Coding Definition
Vibe coding is an AI-assisted approach to software development where you describe what you want to build using natural language prompts, and an AI model generates the corresponding code. Instead of writing every function and class manually, you communicate your intent — the "vibe" of what the software should do — and iterate on the AI's output through follow-up prompts and refinements.
The vibe coding meaning centers on a fundamental shift: development becomes intent-driven rather than syntax-driven. You focus on what the software should accomplish, and the AI handles how to write it.
Origin & Evolution of the Term
The term "vibe coding" was coined by Andrej Karpathy — former Tesla AI director and OpenAI co-founder — in a February 2025 post on X (formerly Twitter). Karpathy described his workflow as one where he would "fully give in to the vibes, embrace exponentials, and forget that the code even exists." He would describe features in natural language, accept the AI's suggestions, and only course-correct when something broke.
The concept resonated immediately. Within months, "vibe coding" entered mainstream developer vocabulary. By late 2025, Collins Dictionary shortlisted it as a word of the year candidate, signaling just how rapidly the idea moved from AI-insider slang to broad cultural awareness.
How It Differs From Traditional Coding
Traditional development is syntax-centric. You write precise instructions in a programming language, manage dependencies, and debug line by line. Vibe coding flips this model.
The shift does not eliminate the need for programming knowledge. It changes where that knowledge matters most — from writing code to reviewing, directing, and architecting it.
How Vibe Coding Works (Process)
Natural Language Prompts
The process starts with a prompt. You describe the feature, function, or application you want in plain language. For example:
- "Build a REST API in Python that accepts a JSON payload with user data and stores it in a PostgreSQL database."
- "Create a React dashboard component that displays a line chart of monthly revenue from this data structure."
The quality of the output depends heavily on the quality of the prompt. Specific, well-structured prompts with clear constraints produce significantly better results than vague requests.
AI Code Generation & Iteration
Once you submit the prompt, the AI model generates the code. This is rarely a one-shot process. The real workflow involves iterative refinement — you review the output, identify gaps or errors, and submit follow-up prompts to adjust.
For instance, after receiving an initial API scaffold, you might prompt: "Add input validation for the email field and return a 422 error for malformed requests." The AI updates the code accordingly. This back-and-forth loop is the core of vibe coding — a conversation between developer intent and AI execution.
Testing & Refinement
AI-generated code must still be tested. This step remains your responsibility. You run unit tests, check edge cases, verify security, and ensure the output aligns with your architectural requirements. Vibe coding accelerates the creation phase, but the validation phase requires the same rigor as traditional development — sometimes more, because AI can produce code that works superficially but contains subtle bugs or inefficiencies.
Popular Vibe Coding Tools & Platforms
Leading AI Coding Assistants
Several AI tools have become central to the vibe coding workflow:
- GitHub Copilot — Integrated directly into VS Code and JetBrains IDEs, Copilot autocompletes code and generates functions from comments. It remains the most widely adopted AI coding assistant.
- Claude Code (Anthropic) — A terminal-based coding agent that can read your codebase, make multi-file edits, and execute commands. Especially strong for complex refactoring tasks.
- ChatGPT (OpenAI) — Widely used for generating code snippets, debugging, and explaining existing code. The Canvas feature allows in-line code editing within the chat interface.
- Gemini (Google) — Google's multimodal model offers code generation within Google AI Studio and is increasingly integrated into Google Cloud workflows.
IDE Integrations & Plugins
The most effective vibe coding tools work where developers already spend their time:
- Cursor — A VS Code fork purpose-built for AI-assisted development. It indexes your entire codebase for context-aware suggestions and supports multi-file edits from a single prompt. Cursor has become the default IDE for many vibe coders.
- JetBrains AI Assistant — Brings AI code generation, refactoring, and explanation directly into IntelliJ, PyCharm, and other JetBrains products.
- Codeium / Windsurf — Free-tier AI assistants that integrate across multiple IDEs and offer autocomplete, chat, and code search.
Emerging Platforms Built for Vibe Coding
A new category of platforms is designed specifically for natural-language-first development:
- Replit Agent — Describe an app in plain language and Replit builds, deploys, and hosts it. Ideal for rapid prototyping and learning.
- Lovable — A platform that converts natural language descriptions into full-stack web applications, targeting non-technical founders and product teams.
- Bolt.new — Browser-based AI coding environment that generates and deploys apps from prompts, with real-time preview.
- Base44 — Focused on building internal tools and business applications through conversational prompts.
Benefits of Vibe Coding
Faster Prototyping & MVP Development
Vibe coding dramatically compresses the time from idea to working prototype. Tasks that previously required days or weeks of manual development can now be completed in hours. Product managers can build functional demos to validate concepts before committing engineering resources. Founders can present working prototypes to investors instead of slide decks.
Lowered Entry Barrier for Beginners
People without formal programming training can now build functional applications. A marketer can create a custom data dashboard. A designer can prototype an interactive UI. This democratization of software creation expands who can participate in building technology — though understanding code still matters for anything beyond simple applications.
Focus on Intent & Logic Over Syntax
Vibe coding frees experienced developers from repetitive boilerplate code. Instead of spending time on syntax, bracket matching, and import statements, you focus on higher-level decisions: system architecture, data flow, user experience, and business logic. The mental energy saved on implementation details can be redirected to design and optimization.
Increased Productivity for Experienced Developers
For senior engineers, vibe coding is a force multiplier. At National Australia Bank, roughly half of production code is now generated by AWS Q Developer, allowing engineers to focus on architecture and code review. AI handles the scaffolding; the developer handles the judgment. When combined with strong coding interview practices, this shift highlights why architectural thinking is becoming the premium skill in technical hiring.
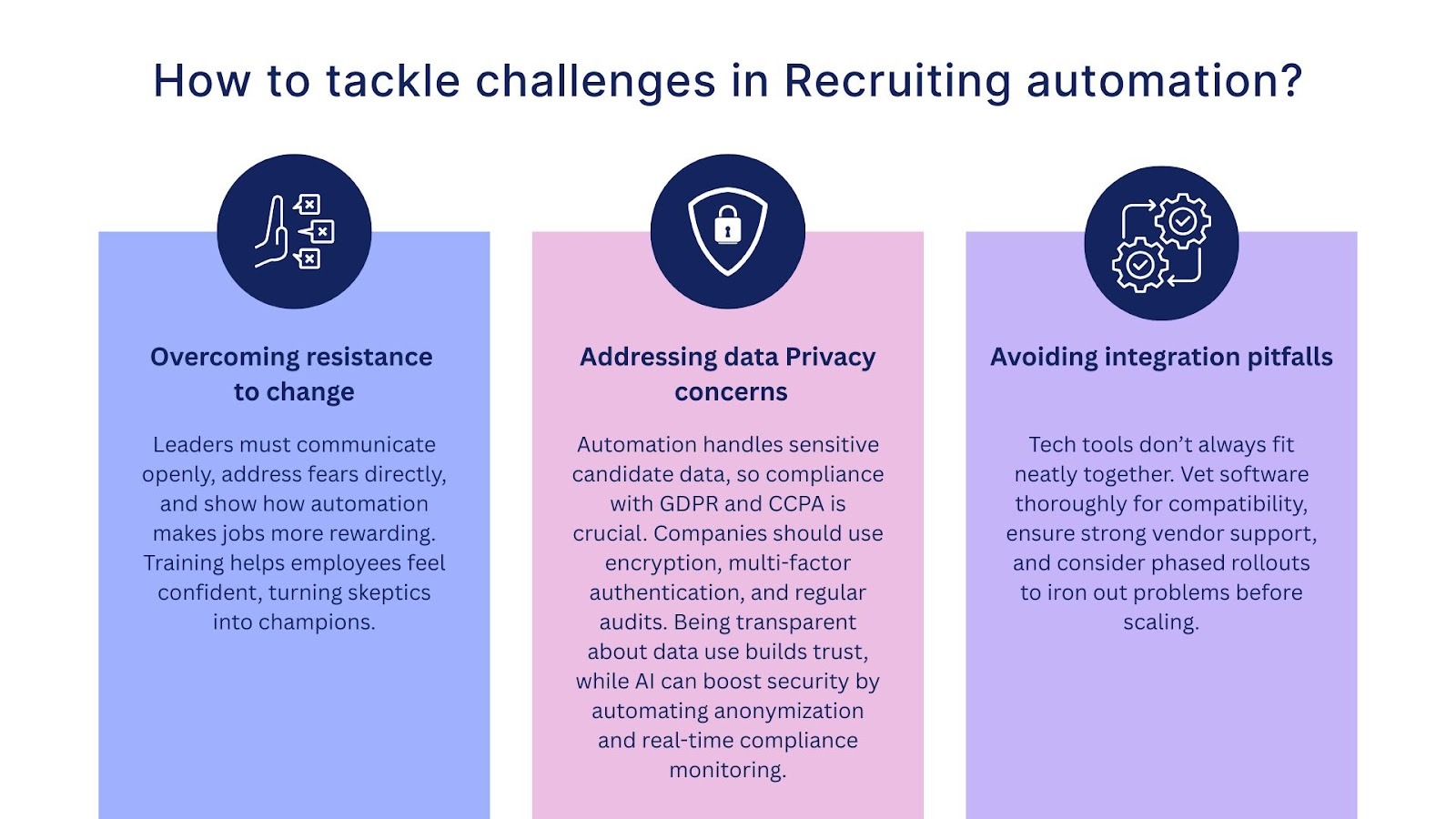
Limitations & Challenges
Code Quality & Security Concerns
AI-generated code can introduce security vulnerabilities that are not immediately obvious. Models may produce code with hardcoded credentials, SQL injection susceptibility, or improper input validation — not because the AI is malicious, but because it optimizes for functional correctness over security hardening. Every line of AI-generated code requires the same security review you would apply to code from a junior developer.
Technical Debt & Maintainability
Rapid code generation can create architectural debt. AI tools often produce code that works but lacks consistent patterns, proper abstraction, or documentation. Over time, this results in codebases that are difficult to maintain, extend, or debug. The speed advantage of vibe coding can become a liability if teams do not enforce code review standards and architectural guidelines.
Need for Human Oversight
AI outputs still require deep, informed review. The developer's role shifts from writer to editor and architect — but that role becomes more critical, not less. Accepting AI-generated code without understanding it creates fragile systems. Organizations that rely on technical assessments to evaluate candidates should now test for code review ability and architectural reasoning, not just the ability to write code from scratch.
Vibe Coding and AI Jobs & Skills
Impact on Developer Roles
Vibe coding is reshaping what it means to be a software developer. Writing code is becoming a smaller portion of the job. Reviewing, directing, and testing AI-generated code — along with system design, architecture decisions, and performance optimization — are where experienced developers add the most value.
This shift affects hiring directly. Companies evaluating technical candidates increasingly need to assess problem-solving and system design skills rather than syntax recall. Platforms designed for AI-assisted technical interviews are adapting their evaluations to reflect this new reality.
New Skill Sets and Courses
A new category of skills is emerging around vibe coding:
- Prompt engineering — Crafting precise, context-rich prompts that produce high-quality code output.
- AI-assisted development workflows — Knowing when to use AI generation, when to write manually, and how to review AI output effectively.
- Architecture-first thinking — Designing systems at a high level before using AI to generate implementation details.
Online courses and bootcamps are beginning to incorporate these skills, though formal "vibe coding courses" are still in early stages. The developers who combine traditional programming knowledge with strong AI collaboration skills will be the most valuable hires.
Job Opportunities Emerging Around AI-Driven Development
New roles are appearing: AI code reviewer, prompt engineer, AI integration specialist, and agent orchestrator. At the same time, existing roles are evolving. Full-stack developers are expected to leverage AI tools as part of their standard workflow. Companies building candidate sourcing strategies for 2026 are already factoring AI-assisted development skills into their job requirements and screening criteria.
Future Trends & Industry Adoption
AI Becoming a First-Class Partner in Development
The trajectory is clear: AI is moving from a code-suggestion tool to a full development partner. Agentic AI systems — agents that can plan, execute, test, and iterate autonomously — are being integrated throughout the software development lifecycle. Tools like Replit Agent and Claude Code already operate at this level for simpler tasks. Within the next two years, expect AI agents to handle multi-step feature development with minimal human intervention.
Toolchain & API Evolution for AI-Friendly Development
Development toolchains are being redesigned for AI collaboration. APIs are becoming more standardized and self-documenting to improve AI comprehension. CI/CD pipelines are adding AI checkpoints for automated code review. Online coding interview platforms are incorporating AI-generated challenges and real-time code collaboration features that reflect how modern development actually works.
How Vibe Coding Could Shape Software Engineering
Vibe coding represents a fundamental shift comparable to the move from assembly language to high-level programming languages. It does not eliminate the need for skilled engineers — it raises the floor of what one person can build while raising the ceiling of what matters in professional software development.
The developers who thrive will be those who use AI to amplify their expertise, not replace their understanding. As Karpathy himself noted, the approach works best when you have enough experience to recognize when the AI gets it wrong. For organizations, the imperative is clear: invest in evaluating and developing the architectural, design, and review skills that define great engineering in the vibe coding era.
Conclusion
Vibe coding is reshaping software development from the ground up. By enabling developers and non-developers alike to build software through natural language prompts, it accelerates prototyping, lowers barriers to entry, and shifts the developer's core value toward architecture, review, and system design.
The technology is powerful but not without risks. Security vulnerabilities, technical debt, and the need for human oversight remain real challenges. The most effective teams will be those that combine AI-assisted speed with disciplined engineering practices.
For hiring teams, the implications are immediate. Evaluating candidates on syntax knowledge alone is no longer sufficient. Assessing architectural thinking, code review ability, and AI collaboration skills is now essential. Tools like HackerEarth FaceCode enable real-time technical interviews that test exactly these higher-order skills — ensuring your hiring process keeps pace with how software is actually being built today.
Frequently Asked Questions
What is vibe coding?
Vibe coding is an AI-assisted software development approach where you use natural language prompts to generate code. Instead of writing every line manually, you describe your intent and an AI model produces the code, which you then review, test, and refine. The term was coined by Andrej Karpathy in February 2025.
Is vibe coding the future of software development?
Vibe coding is becoming a significant part of software development, especially for prototyping, MVPs, and internal tools. However, complex production systems still require experienced engineers for architecture, security review, and optimization. It is more accurate to view vibe coding as an evolution of the developer's toolkit rather than a complete replacement for traditional development.
Can non-developers use vibe coding?
Yes. Platforms like Replit Agent, Lovable, and Bolt.new allow people without formal programming training to build functional applications using natural language descriptions. However, building anything beyond simple applications still benefits from understanding programming fundamentals, debugging, and system architecture.
What tools support vibe coding?
Leading vibe coding tools include GitHub Copilot, Cursor, Claude Code, ChatGPT, Replit Agent, Lovable, and Bolt.new. IDE integrations for VS Code and JetBrains bring AI assistance directly into existing developer workflows. The best tool depends on your use case — Cursor and Claude Code suit experienced developers, while Replit and Lovable target rapid prototyping and beginners.
Does vibe coding replace traditional developers?
No. Vibe coding changes what developers spend their time on, shifting the focus from writing code to reviewing, directing, and architecting it. The need for experienced engineers who understand system design, security, and performance optimization increases as AI-generated code becomes more prevalent. Human oversight remains essential for production-quality software.
Are there risks to vibe coding?
Yes. Key risks include security vulnerabilities in AI-generated code, accumulation of technical debt from inconsistent code patterns, and the danger of accepting AI output without thorough review. Organizations must maintain rigorous code review standards and security testing regardless of whether code is written by a human or generated by AI.



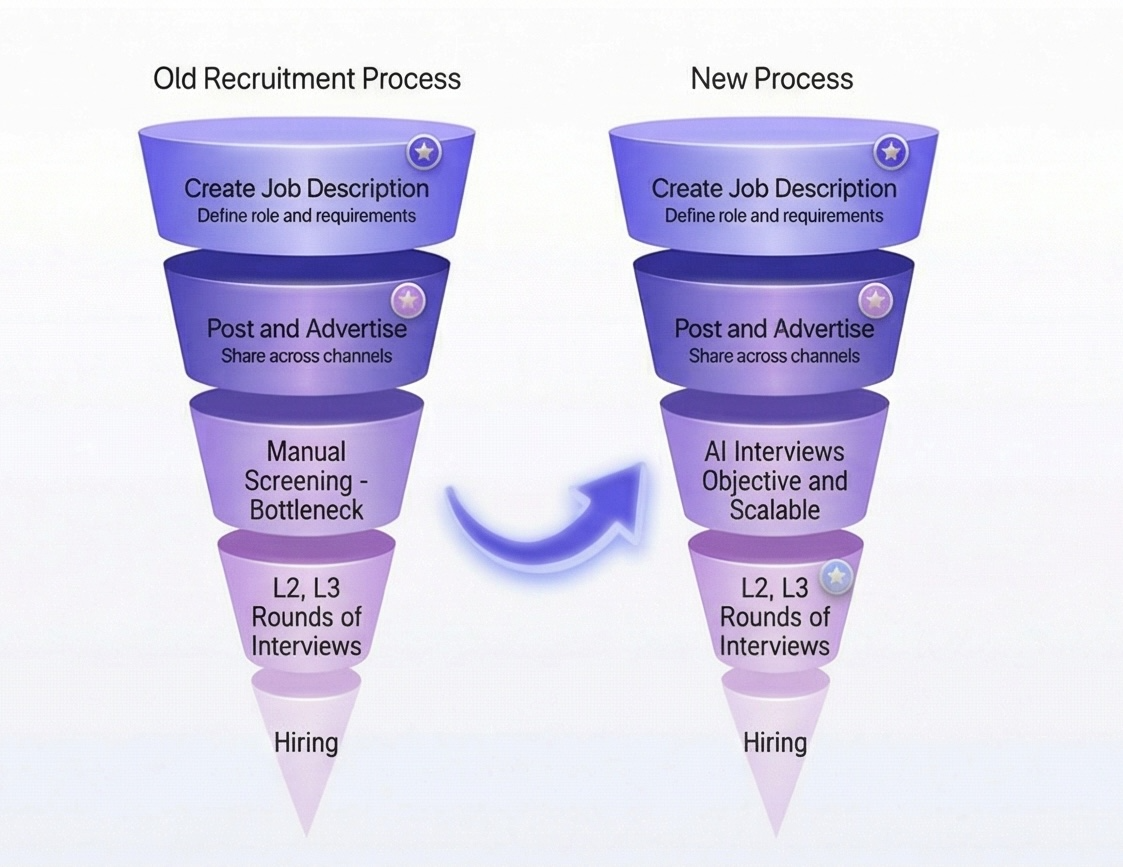




























 Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.
Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.










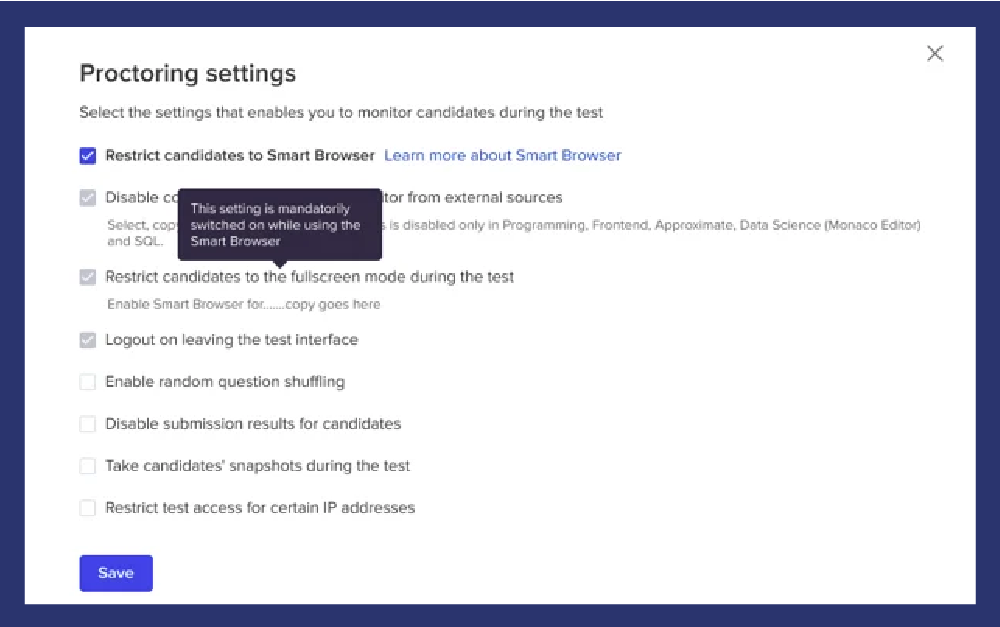
 Our AI-enabled Smart Browser takes frequent snapshots via the webcam, throughout the assessment.
Consequently, it is impossible to copy-paste code or impersonate a candidate.The browser prevents the following
candidate actions and facilitates thorough monitoring of the assessment:
Our AI-enabled Smart Browser takes frequent snapshots via the webcam, throughout the assessment.
Consequently, it is impossible to copy-paste code or impersonate a candidate.The browser prevents the following
candidate actions and facilitates thorough monitoring of the assessment:



