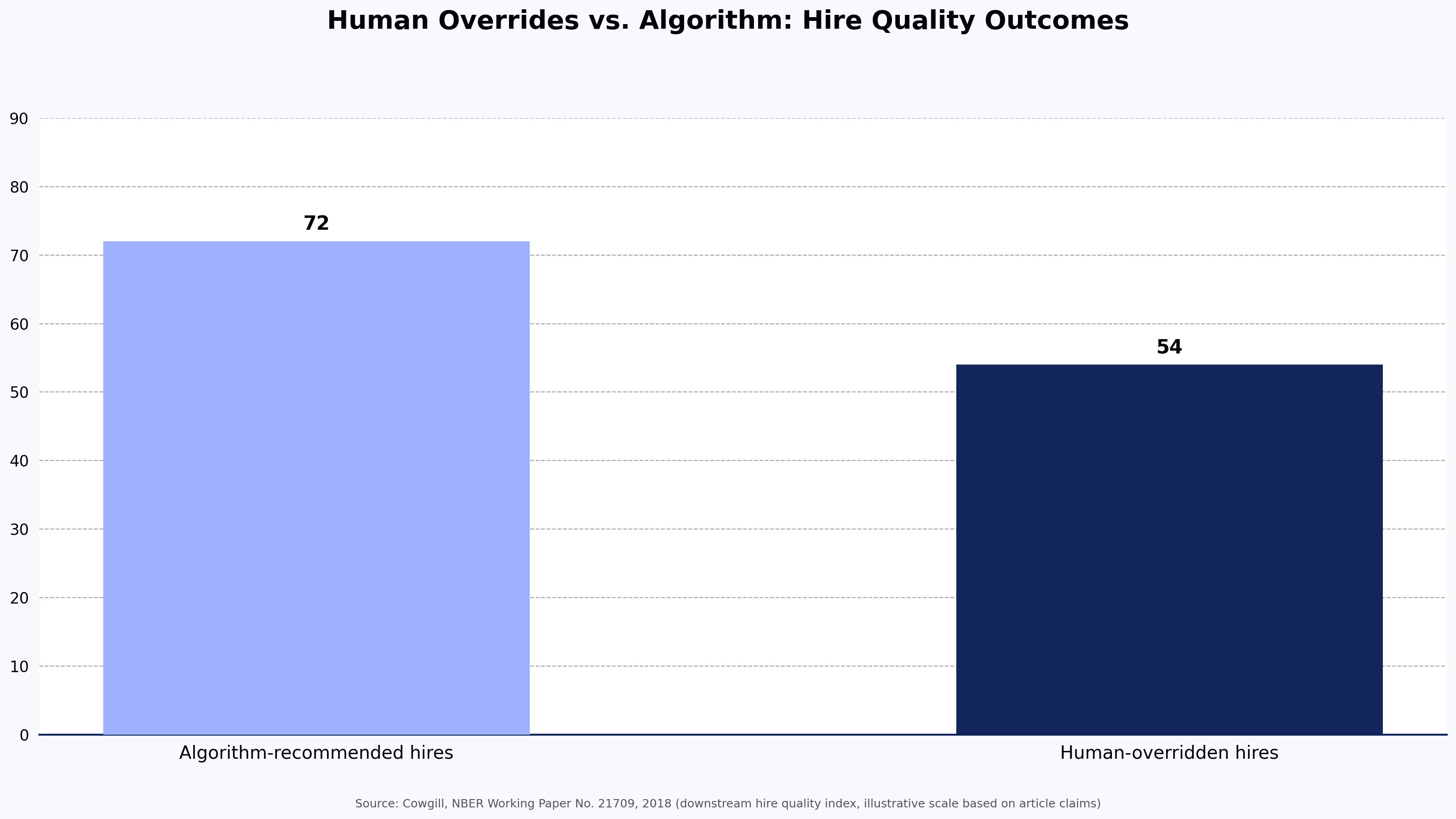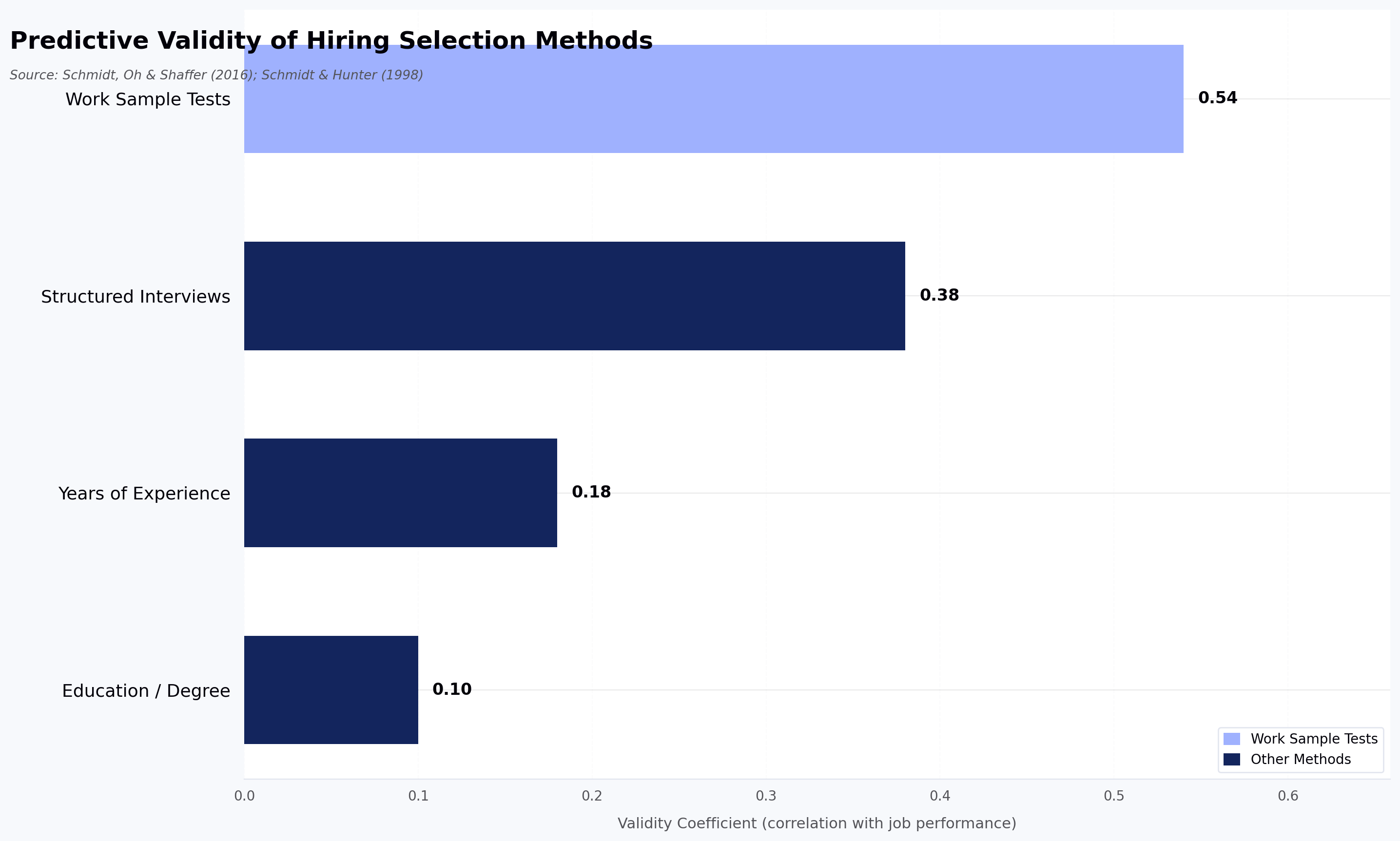




Hackathon problem statements that actually test real developer skills
Technical hackathons have changed from informal meetups to serious events where developers prove their skills. As more companies focus on skill-based hiring, both organizers and participants need to be able to create and solve strong problem statements. Simple prompts like "build a better app" are no longer enough. Top events now require complex challenges that test architecture, security, and the use of new protocols such as the model context protocol or agentic orchestration.
What makes a hackathon problem statement actually good?
A good problem statement gives clear direction but still leaves room for creative solutions. What separates a simple project from a standout one is real-world difficulty. This challenge often comes from things like strict data limits, the need to work with old systems, or having to consider ethical and security issues.
A strong problem statement follows the SMART framework: specific, measurable, achievable, relevant, and time-bound. For example, instead of asking for a general "sustainability app," a better prompt would ask for a way to reduce data center water use by fifteen percent using an AI-powered cooling system. This level of detail lets judges measure solutions with clear metrics instead of just going by feel.
Adding an "agentic layer" or "security layer" is a key part of today’s advanced challenges. When developers have to build features like automated triage or vulnerability scanning, they start thinking more like systems architects than just feature builders. Since 92% of developers now use AI tools, the real test is not just using them, but using them responsibly and at scale.
How to write a problem statement (step-by-step)
Writing a good problem statement is a special skill. It takes empathy for the end-user and a solid grasp of the technology involved. Start by finding the root cause of the problem, not just the obvious symptoms, to uncover the real business or social issue.
Step 1: Identify the stakeholder pain points
Before writing anything, organizers should do primary research and talk to people affected by the problem. This could mean visiting a production floor to see equipment issues or looking at support tickets to spot common customer complaints. In company hackathons, big tech problems like technical debt—which takes up 42% of developer time often make the best problem statements.
Step 2: Define the five Ws and the baseline data
A strong problem statement answers the five Ws: who is affected, what the problem is, when and where it happens, and why it matters. It should also include data. For example, instead of saying "support tickets are slow," say "IT support tickets for database access take an average of 48 hours to resolve, affecting 500 engineers’ productivity."
Step 3: Contrast current and future states
The best challenges clearly show the difference between the current state and the desired future state. This gap sets the goal for developers. The future state should be clear but not overly detailed—it should describe the result, like "automated ticket resolution with 90% accuracy," without telling developers which tools to use.
Step 4: Layer in technical requirements and evaluation criteria
To really test developer skills, the problem statement should list required technologies and quality standards. This might mean asking for modular code, a full set of tests (like at least 70 test cases), and following industry coding standards.
Gen AI hackathon problem statements (3 levels)
Generative AI has raised the bar for hackathon projects. A basic chatbot, once a big achievement, is now just a starting point. To challenge today’s developers, gen AI problem statements should focus on details like retrieval, grounding, and safety.
Level 1: Contextual prompt engineering and basic RAG
The objective here is to move beyond simple "zero-shot" prompting. Developers are challenged to build a system that utilizes a local knowledge base to provide grounded answers.
- Problem: A university's student handbook is a 300-page PDF that is difficult to search, leading to repetitive questions for administrative staff.
- Task: Build a "Handbook Copilot" that uses a vector database to retrieve relevant sections and provide cited answers to student queries.
- Goal: Demonstrate an understanding of embeddings, chunking strategies, and basic retrieval-augmented generation (RAG).
Level 2: Multimodal integration and agentic reasoning
At this stage, developers need to work with different types of data and build logic that can handle multi-step tasks.
- Problem: Fashion researchers spend hundreds of hours manually tagging social media images to identify emerging trends.
- Task: Create a "Style Weaver" that extracts visual elements (colors, textures, styles) from images using computer vision and synthesizes these with text analysis (hashtags, captions) to predict the next season's trending palette.
- Goal: Integrate vision-language models with clustering algorithms to provide actionable business intelligence.
Level 3: Enterprise-grade reliability and sentinel auditing
The toughest gen AI challenges focus on trust, transparency, and preventing AI from making things up.
- Problem: Financial institutions cannot deploy LLMs for customer-facing advice due to the high risk of hallucinated data causing regulatory breaches.
- Task: Develop a "Sentinel AI" system that runs two independent LLMs in parallel for every query. A third "Audit Agent" must cross-validate their outputs, perform a consistency check, and flag any discrepancy or toxic content before it reaches the user.
- Goal: Build a self-auditing architecture that meets enterprise compliance and safety standards.
Agentic AI hackathon problem statements (3 levels)
Many are calling 2025 the "year of AI agents," as we move from passive models to active assistants that can plan and carry out complex tasks. Problem statements here should focus on teamwork between agents and the model context protocol (MCP).
Level 1: The digital assistant for repetitive workflows
The aim is to automate one clear business process using a digital skill.
- Problem: HR teams spend 20% of their time manually responding to emails about leave policies and updating internal trackers.
- Task: Build an agent that monitors a specific inbox, answers policy questions using a provided wiki, and—upon receiving a formal request—automatically updates a mock HR database.
- Goal: Demonstrate basic agentic orchestration and "tool-call" capabilities.
Level 2: The deep research meta-agent
This stage tests whether you can manage a team of specialized sub-agents working together, either in a group chat or as part of a state machine.
- Problem: Professional analysts require structured research reports that draw from diverse web sources, academic papers, and financial filings.
- Task: Design an agent called "Apollo" that manages two sub-agents: "Athena" (the search engine) and "Hermes" (the analyzer). Athena gathers data using advanced web-search APIs, while Hermes checks for knowledge gaps and requests more information until the research itinerary is complete.
- Goal: Implement a two-stage synthesis process where section-specific content is generated before a final, cited report is assembled.
Level 3: The industrial "risk-wise" orchestrator
The most advanced level asks agents to work with real-world systems and unpredictable market data.
- Problem: Global supply chains are susceptible to port delays, geopolitical shifts, and sudden tariff changes that cost companies billions annually.
- Task: Build a "Supply Chain Risk Analysis System" that leverages AI agents to monitor shipping schedules and news feeds in real-time. The system must use MCP to interact with SQL databases containing historical tariff data and Azure AI services to predict potential disruptions before they occur.
- Goal: Create a professional, dashboard-driven system that provides "explainable" risk scores and automated mitigation strategies.
AI ML hackathon problem statements (3 levels)
Traditional AI and machine learning are still important for predictive analytics and computer vision, especially where text-based deep learning isn’t the main focus. These challenges test the basics: data prep, model training, and deploying as a scalable API.
Level 1: Predictive analytics for health and wellness
This level is about classic regression and classification tasks with structured sensor data.
- Problem: Rising sedentary lifestyles have led to an increase in preventable workplace injuries and chronic fatigue.
- Task: Develop a system that analyzes heart rate variability and motion data from wearable devices to predict "fatigue warnings" and suggest adaptive routines.
- Goal: Implement a clean ML pipeline using Scikit-learn or TensorFlow Lite for edge devices.
Level 2: Computer vision for industrial or agricultural automation
At the intermediate level, challenges involve image processing and specialized classification.
- Problem: Agricultural researchers in rural regions struggle with the manual classification of cattle and buffalo breeds, which is essential for genetic improvement and disease control.
- Task: Build an "Auto Recording of Animal Type Classification System" that uses images to extract body structure parameters (length, height, rump angle) and generates objective classification scores.
- Goal: Deploy a robust CNN model capable of handling diverse environmental backgrounds and lighting conditions.
Level 3: Real-time anomaly detection for fraud and cybersecurity
At the expert level, you need to process streaming data quickly and with high accuracy.
- Problem: Financial institutions face "sophisticated fraud" that evolves faster than traditional rule-based systems can detect.
- Task: Create a "Real-Time Intrusion Detection Dashboard" that processes network traffic and transaction logs to detect anomalies such as brute-force attempts or unauthorized access patterns using ensemble methods and transfer learning.
- Goal: Build a system that visualizes alerts with severity scores and recommends immediate defensive actions.
Web development hackathon problem statements (frontend, backend, full-stack)
Web development hackathons have grown from simple one-page projects to complex full-stack events that require professional standards. These challenges test if developers can build systems that are scalable, maintainable, and secure.
Frontend: Immersive experiences and state management
Frontend challenges now focus on performance and using modern UI frameworks like React 19.
- Problem: Global data centers consume massive amounts of energy, partially driven by inefficient "infinite scroll" designs that download data the user never sees.
- Task: Create a "Slow Your Scroll" web application that uses advanced virtualization and lazy-loading techniques to minimize data download while maintaining a smooth user experience.
- Goal: Demonstrate mastery of the DOM, accessibility (A11y), and energy-efficient web design.
Backend: Scalable infrastructure and api orchestration
Backend challenges are at the core of the app: security, database logic, and API performance.
- Problem: Small businesses struggle with "invoice reconciliation," manually matching bank payments to thousands of outstanding bills across different currencies.
- Task: Build a "Seamless Invoicing & Reconciliation API" that handles bulk uploads, automates the matching process using fuzzy logic, and integrates with third-party payment gateways like UPI or Stripe.
- Goal: Architect a system using Node.js or Python that emphasizes security (JWT), scalability, and robust error handling.
Full-stack: The "full-stack forge" battle for supremacy
Full-stack challenges ask you to build a complete system, often with strict requirements for lines of code and testing.
- Problem: Remote villages lack access to specialized medical advice, and existing telemedicine apps are too heavy for low-bandwidth environments.
- Task: Develop a "Lightweight Telemedicine Platform" that includes a responsive React/Next.js frontend and a Node.js/FastAPI backend. The system must support asynchronous messaging, low-res image uploads for diagnosis, and a "doctor's portal" for managing patient files.
- Goal: Deliver a project with at least 5,000 LOC and 70+ test cases, following a modular "separation of concerns" architecture.
How to pick the right problem statement
For developers, picking the right challenge is a key decision that affects how visible and successful their project will be. For organizers, it can mean the difference between a great event and lots of unfinished projects.
For developers: The impact vs. feasibility matrix
Developers should choose an idea they can finish within the hackathon’s time limit (usually 48 hours) and that has real-world value.
- Validation: Spend time brainstorming. Make sure your team understands all the dependencies, bottlenecks, and priorities before you start coding.
- The MVP approach: Aim to deliver a minimum viable product that solves the main problem, instead of building a large, unfinished system.
For organizers: The "innovation moat" check
Organizers should make sure their problem statement creates an "innovation moat" something that pushes teams to go beyond common solutions.
- Feasibility check: Can the problem be reasonably solved or prototyped in the given timeframe?
- Business value: Does the solution have the potential to boost earnings or transform access to a critical service?
- AI-First thinking: Is the use of AI core to the solution, or is it merely an "after-thought" or a simple wrapper?
Conclusion: The future of hackathons is autonomous and ethical
Looking ahead to 2025 and 2026, hackathon problem statements show that coding will be just one part of a developer’s role. As AI agents get smarter, the focus will shift to system orchestration, ethics, and responsible deployment. Developers will be judged not only on how efficient their code is, but also on how transparent their AI’s reasoning is and how strong their security measures are.
For organizers, the real challenge is building vibrant communities that can address big issues like climate change and financial inclusion through open-source teamwork and secure coding. By offering strong, data-driven problem statements with professional structure, hackathons can keep driving both personal growth and industry-wide innovation.