How to use an AI interview agent to screen automation testing candidates
Read time: 10 minutes
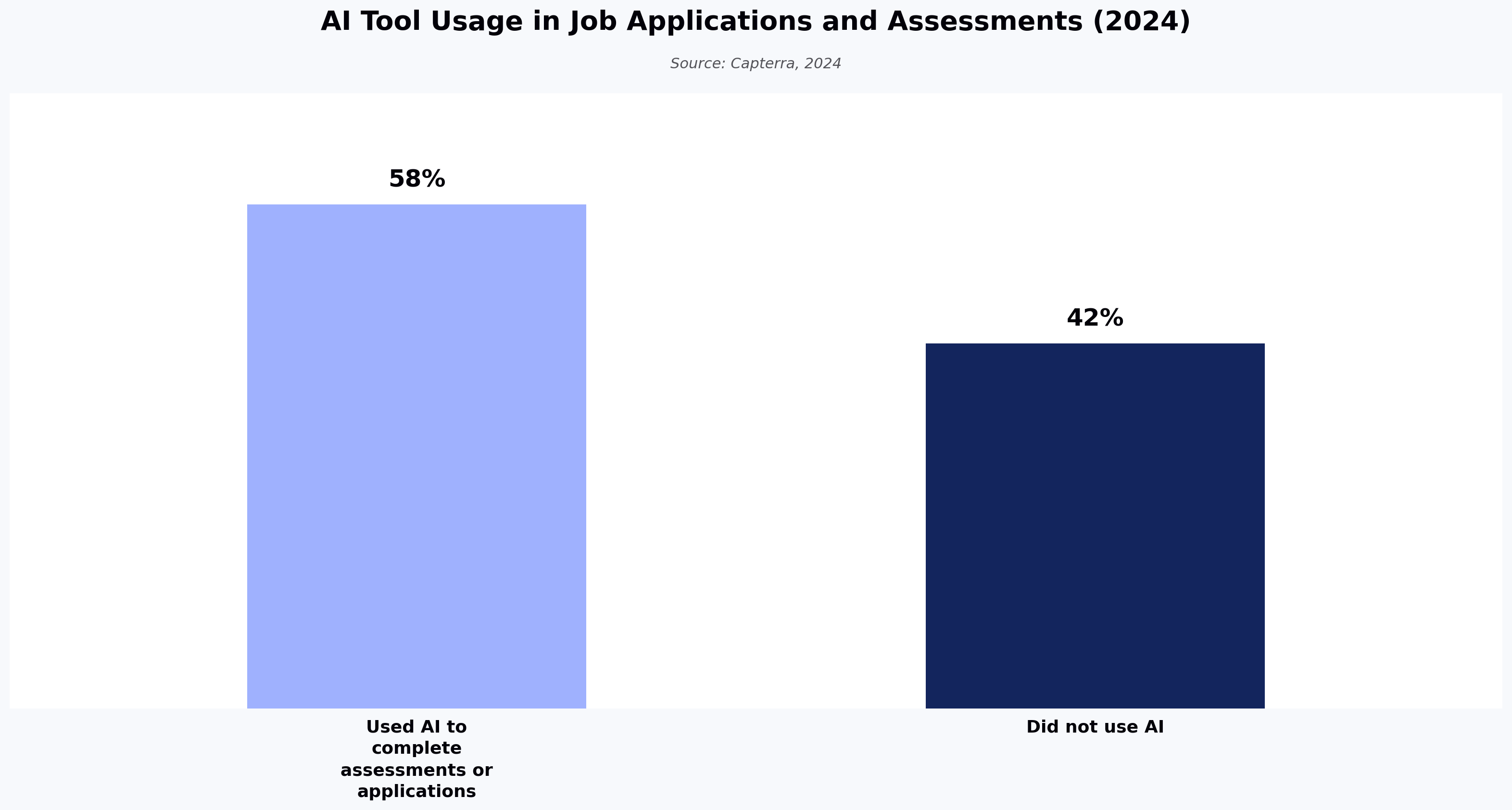
An AI interview agent is an autonomous system that conducts structured first-round technical interviews — asking role-specific questions, evaluating live code, and generating scored reports — without human involvement. For automation testing roles, an AI interview agent to screen automation testing candidates augments manual resume reviews and phone screens with skill-specific evaluations that surface genuine framework proficiency. Recruiters tell us roughly half the candidates who list Selenium on their resume cannot write a working test script — less a matter of dishonesty than of how dramatically the barrier to looking qualified has dropped. According to Capterra, 58% of candidates used AI tools to complete job assessments or applications in 2024, and the Identity Theft Resource Center reported a sharp rise in resume and application fraud over the same period. When AI can generate a polished application in minutes, credentials and self-reported experience stop functioning as reliable filters for automation testing screening — and recruiters cannot validate framework depth from a resume alone, while engineering managers cannot screen every applicant.
This guide gives you a step-by-step implementation path for using an AI interview agent to screen automation testing candidates. You will learn how to design a skill rubric, configure question types, set up integrity safeguards, and integrate the agent into your existing ATS workflow for technical screening and candidate evaluation.
Why automation testing roles are uniquely hard to screen
Automation testing resumes are keyword-dense by nature. A candidate who completed a weekend course may list Selenium, Cypress, TestNG, Jenkins, and Docker on their resume. Another candidate with five years of Page Object Model (a test design pattern that wraps UI elements into reusable classes) and CI/CD pipeline integration experience may list many of the same terms. Keywords tell you little about proficiency level, and resumes are often where the signal ends.
1. Recruiters cannot reliably validate technical depth
Your recruiters compound the problem through no fault of their own. Most technical recruiters can confirm that a candidate has used Selenium. They cannot confidently assess whether that candidate understands dynamic wait strategies, data-driven testing patterns, element locator design (how tests find and target UI components), or cross-browser test orchestration.
This is not a recruiter skills gap. It is a structural mismatch between recruiter expertise and what automation testing roles actually demand.
2. Traditional screening methods are losing effectiveness
Take-home assignments once helped bridge this gap, but they are weakening under two pressures. Completion rates drop sharply when candidates face lengthy exercises. AI-generated submissions are also becoming harder to distinguish from genuine work without live verification.
Companies that rely on phone screens face a similar issue. A 30-minute call can gauge communication and enthusiasm, but it cannot reveal whether someone can debug a flaky test suite or architect a maintainable automation framework.
3. AI has flattened candidate differentiation
There is also a convergence problem. AI-prepped candidates now deliver polished, STAR-formatted answers to behavioral questions about automation testing experience. When every candidate sounds rehearsed and uses similar structure, polish stops being a useful signal. Your interview automation process must shift from what candidates say to what they can demonstrably build and explain in real time.
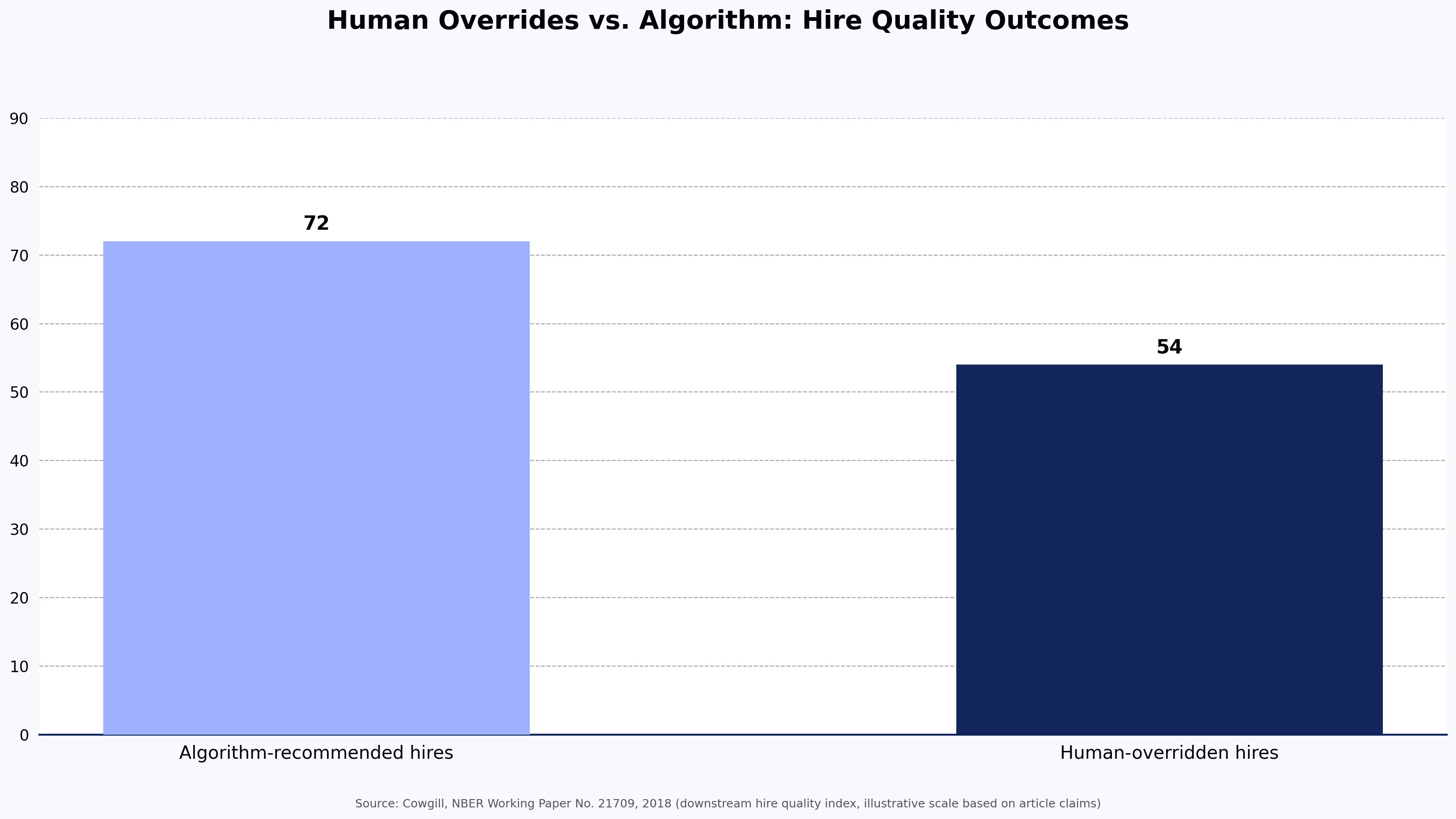
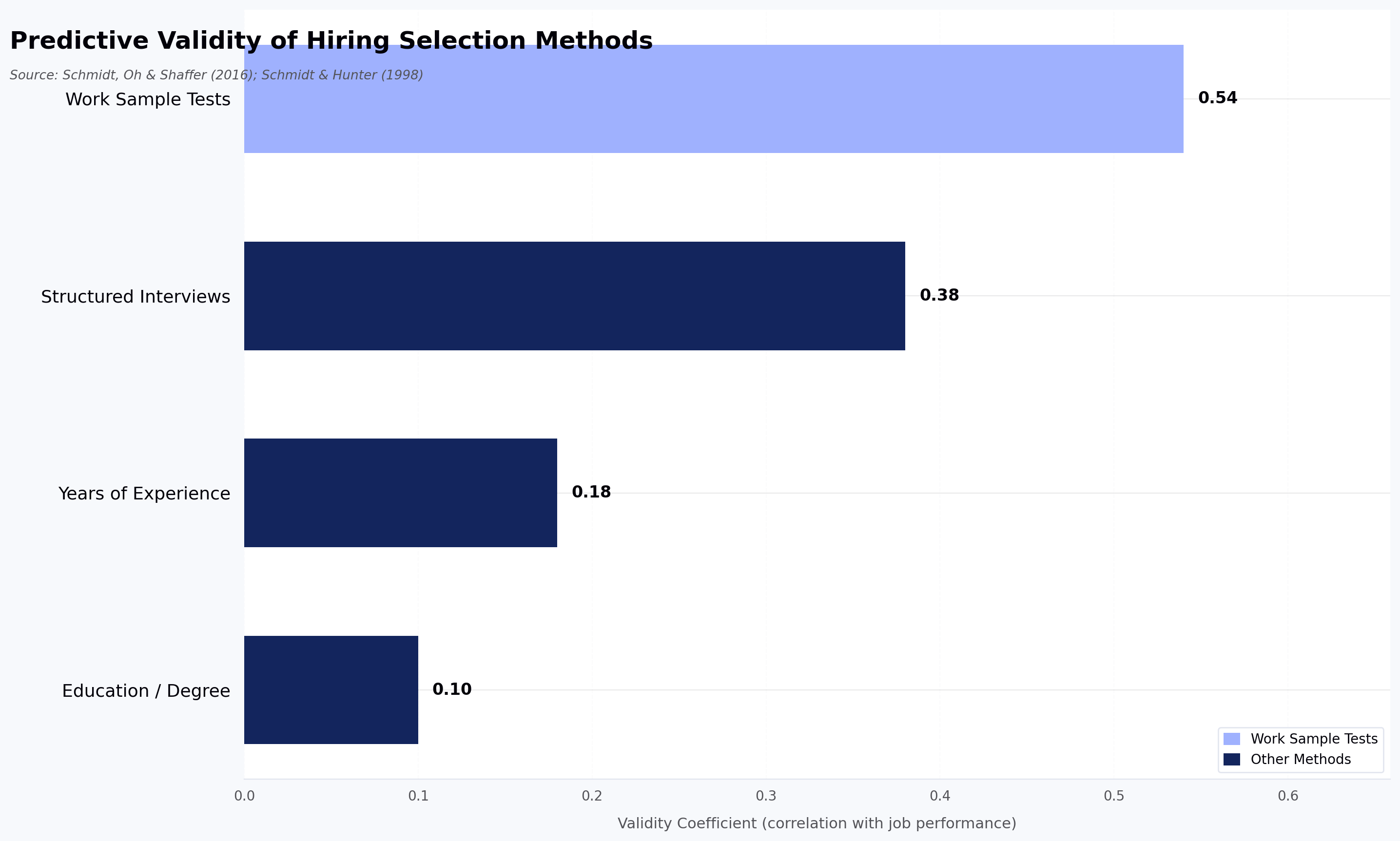
4. Structured interviews create better hiring signals
Some meta-analytic research, including widely cited work by Frank Schmidt and John Hunter, suggests structured interviews can yield meaningfully higher predictive validity for job performance compared to unstructured interviews, as summarized by SHRM. An AI interview agent brings that structure to the screening stage, where it has historically been absent.
What an AI interview agent actually does (and doesn't do) to screen automation testing candidates
Before you configure anything, you need a clear picture of what an AI interview agent handles and where its limits are.
An AI interview agent is an autonomous system that conducts structured technical and behavioral interviews without human involvement. It evaluates candidate responses against predefined rubrics, generates scored, evidence-based reports, and delivers the results to your hiring team. Think of it as a consistent, always-available first-round interviewer that applies the same standard to every candidate regardless of time zone, hiring volume, or interviewer availability.
The table below summarizes the core capabilities and explicit limits of an AI interview agent in an automation testing context.
| What It Does | What It Does Not Do |
|---|---|
| Runs structured first-round interviews | Replace final-round human interviews |
| Tests role-specific automation skills | Guarantee a perfect hire |
| Evaluates coding performance against a rubric | Work well with generic setup |
| Generates scored reports | Replace manager judgment |
| Supports asynchronous screening across time zones | Measure presentation over substance |
| Applies a consistent rubric to every candidate | Remove all hiring risk |
For automation testing screening, a well-configured agent handles several critical functions.
- It conducts role-calibrated conversations that adapt to candidate responses, asking Selenium, Cypress, or API testing questions and adjusting the line of inquiry as the candidate answers.
- It evaluates submitted code against a configured rubric — typically through a combination of automated test case execution, static analysis, and LLM-assisted rubric matching against criteria you define — assessing logic, efficiency, and adherence to common patterns.
- It generates structured scorecards with scoring rationale for every evaluation dimension, giving your engineering manager reviewable evidence instead of a vague thumbs-up.
- And it does all of this at scale, running many simultaneous interviews with rubric-applied evaluation that does not vary by interviewer mood or fatigue. While no automated system is free of bias, applying the same rubric to every candidate is typically more consistent across candidates than human-led screens.
What the agent does not do is equally important.
- It does not replace final-round human interviews for senior roles where architecture discussions and team-fit evaluation require human judgment.
- It does not guarantee a perfect hire; it improves signal quality at the screening stage, not at the offer stage.
- It does not produce useful results without proper configuration, because a generic rubric produces generic evaluations.
- And it does not measure presentation over substance. Some AI video interview tools assess surface-level proxies like eye contact and speech cadence.
The better-configured agents evaluate output, not optics. If your candidate writes a working Selenium script that handles dynamic waits correctly, that matters far more than their webcam posture.
When an AI interview agent is the wrong tool
AI interview agents are not the right fit for every hiring scenario. If your annual automation testing hiring volume is in the single digits, the configuration effort may outweigh the time savings. Roles where the primary signal is a portfolio of prior work (e.g., open-source test framework contributions) are better evaluated through code review than synchronous assessment. And in jurisdictions with specific AI hiring regulations — such as New York City Local Law 144 or Illinois' AI Video Interview Act — you may need bias audits, disclosures, or candidate consent workflows before deploying any automated screening tool. Confirm legal requirements with counsel before rollout.
One concern deserves honest acknowledgment. A 2024 Tidio survey reported that a majority of job seekers expressed reservations about AI-driven video interviews lacking human interaction. (Tidio is a vendor rather than an independent research body; treat the figure as directional and consider supplementing with independent HR research before publication.) The response is not to avoid AI screening but to design the candidate experience deliberately around it: provide clear instructions before the assessment begins, explain how the evaluation will be used, allow candidates to retake practice questions, offer a human point of contact for technical issues, and share scorecard summaries where policy allows. When the agent handles first-round verification well, your engineering manager spends their limited interview time on system design philosophy and problem-solving approach instead of retesting Selenium basics — which often improves the candidate experience in the rounds that matter most.
HackerEarth's AI Interview Agent (OnScreen) puts this approach into practice, using role-calibrated conversations to conduct structured AI interviews and drawing on HackerEarth's broader assessment library, which covers 40+ programming languages and 1,000+ skills. For a broader look at how AI interviewers fit into modern recruiting workflows, see this Complete Guide for Recruiters.
Step-by-step: configuring an AI interview agent to screen automation testing candidates
Configuring an AI interview agent for automation testing roles requires intentional choices at four stages: rubric design, question selection, integrity safeguards, and workflow integration. Shortcut any of these, and the agent will underperform.
Step 1: Define the automation testing skill rubric
Your job description says "3+ years Selenium experience." Your rubric needs to define what that means in evaluative terms. Map the dimensions your AI interview agent will assess. For a mid-level automation testing role, these typically include:
- Core framework proficiency: Selenium WebDriver, Cypress, Playwright, or Appium, depending on the tech stack
- Test architecture: Page Object Model, Screenplay Pattern (a design pattern that separates actors, tasks, and abilities), data-driven testing, and keyword-driven frameworks
- Programming language depth: Java, Python, JavaScript, or TypeScript as applied specifically to test automation
- CI/CD integration: Jenkins, GitHub Actions, GitLab CI, or CircleCI pipeline configuration and test execution
- API testing: REST Assured, Postman/Newman, or framework-native API testing capabilities
- Debugging and maintenance: Flaky test handling, dynamic waits, element locator strategies, and test data management
Weigh these dimensions according to the role's actual priorities. For a mid-level position, framework proficiency and test architecture might carry 40% of the total score, CI/CD integration 20%, and communication skills 10%. Avoid the common mistake of using a generic QA assessment that evaluates manual testing concepts, such as the defect lifecycle, rather than automation-specific skills. The wrong rubric will screen for the wrong profile, no matter how capable the AI agent is. Platforms like HackerEarth's Technical Assessments let you upload a job description, auto-generate a role-specific assessment, and customize it from a library spanning a wide range of skills and languages — useful when you need to translate a generic rubric into role-calibrated questions quickly.
Step 2: Select and configure the right question types to screen automation testing candidates
The rubric tells the agent what to evaluate. Question types determine how. When you select question types for your AI interview agent to screen automation testing candidates, you are deciding what evidence the scorecard will rest on.
Coding challenges place the candidate in a sandboxed IDE to write real automation test code. Example: "Write a Selenium WebDriver script that navigates to a login page, enters credentials from a data file, and verifies the dashboard loads within 3 seconds." The AI evaluates code quality, logic, efficiency, and adherence to common automation patterns.
Architecture questions test structural thinking. Ask the candidate to design a test automation framework for a microservices application with 15 services and independent deployment pipelines. The agent evaluates depth of reasoning, not keyword density.
Debugging scenarios present broken test scripts with common automation issues: stale element references, incorrect locator strategies, misused implicit waits, and hardcoded test data. The candidate identifies and fixes each problem, while the agent tracks the candidate's diagnostic approach.
Behavioral questions surface real-world experience. "Describe a time you maintained a large test suite that became unreliable" reveals communication clarity and problem-solving methodology beyond what any resume conveys.
The critical differentiator across all question types is the agent's role-calibrated conversation. When a candidate mentions Page Object Model, the agent can probe further: "What are its limitations, and when would you choose an alternative pattern?" This is where memorized definitions tend to fail. Candidates who prepped with ChatGPT can recite textbook answers, but they often cannot navigate unpredictable follow-up depth. Recruiters worry that AI screening tools miss qualified candidates due to rigid filtering. Calibrated follow-ups address this concern directly by finding each candidate's actual proficiency boundary rather than applying a binary pass/fail on a single answer.
Step 3: Set up integrity and proctoring safeguards
For roles where AI-generated submissions are a real risk, this step determines whether the assessment measures automation skill or prompt-engineering ability. AI-assisted cheating on coding assessments is now well-documented — candidates can paste a prompt into ChatGPT and receive working Selenium code in seconds. Without proctoring, your assessment may measure prompt-engineering ability rather than automation-testing competency.
Layer your defenses in two tiers.
Must-have (table stakes):
- Tab-switching detection flags when candidates navigate away from the assessment environment.
- AI-based plagiarism detection compares submitted code against known AI-generated patterns and other submissions.
- Copy-paste prevention blocks externally generated code from entering the IDE.
Nice-to-have (higher-stakes or senior roles):
- Webcam monitoring and screen capture verify identity and detect suspicious behavior.
- Extension detection identifies browser tools providing real-time AI assistance.
Balance firmness with candidate experience. Proctoring that feels like interrogation drives top candidates out of your pipeline.
Prioritize code replay capability across both tiers. After the assessment, your team watches a keystroke-by-keystroke playback of how the candidate built their solution. Fluent, iterative typing signals genuine knowledge. Large pasted code blocks or sudden jumps in complexity signal external help. This evidence trail gives engineering managers confidence before they invest their own time in a live interview.
Step 4: Integrate the AI agent into your existing hiring workflow
Results that live in a separate platform will not be used. The output of an AI interview agent to screen automation testing candidates must flow directly into the systems your team already works in.
ATS integration
Connections to your applicant tracking system ensure candidate scores, code replays, and AI-generated summaries appear inside your recruiter's existing workflow without manual data transfer or platform switching. Confirm which ATS integrations are available for your plan with your vendor.
Workflow placement
The AI interview agent supplements the manual phone screen rather than replacing the final-round interview. Your funnel becomes: Application → AI interview agent screening → Recruiter reviews shortlisted candidates → Live technical interview with engineering → Offer. This preserves the human touchpoints candidates value while removing the bottleneck that slows your pipeline.
Asynchronous scheduling
This eliminates timezone coordination entirely. Candidates receive a link, complete the interview on their own schedule, and results appear in your dashboard within minutes. For global automation testing hiring, this alone can shave days off the screening cycle.
Stakeholder visibility
Give engineering managers read access to scorecards and code replays before the live interview. With that context, the live conversation focuses on architecture decisions and cross-team collaboration style rather than retesting framework fundamentals.
Screening automation testers with confidence starts with the right setup
The gap between an automation testing job posting and a qualified hire is a screening problem. Resumes overstate proficiency, take-home assignments invite AI-generated submissions, and phone screens filter for confidence rather than competency. Every day your team spends on manual screening is a day the role stays open, and release cycles slow down.
An AI interview agent helps close that gap when you configure it with intention. Define a rubric that maps to real automation testing work — not just resume keywords. Select question types that force candidates to write, debug, and explain code under observed conditions. Layer proctoring safeguards that verify authenticity without alienating strong candidates. Then integrate the agent directly into the ATS your recruiters already use so that results reach the right stakeholders without extra steps.
If you want to compare your current screening setup against the four steps above, start by auditing your existing automation testing rubric for the dimensions listed in Step 1 — most teams find at least two gaps on first review.
Next steps: see it in action
Book a demo to see how HackerEarth's AI Interview Agent fits your open automation testing roles.
FAQs
1. How long does it take to configure an AI interview agent for an automation testing role?
In our experience working with hiring teams, most can go from job description to live assessment in roughly an hour, though actual timing depends on team familiarity and role complexity. Setup time typically breaks down across JD upload and auto-generation, rubric weighting, question customization from the library, and proctoring configuration. The longest stage tends to be question customization for niche roles — mobile automation with Appium, for example, or specialized API testing frameworks — where you may want to review or supplement library questions to match your stack precisely.
2. Can an AI interview agent evaluate both junior and senior automation testers?
Yes, if you configure separate rubrics for each level. A junior rubric might focus on core Selenium scripting and basic locator strategies, while a senior rubric emphasizes framework architecture, CI/CD pipeline design, cross-browser orchestration, and mentoring approach. Role-calibrated conversations automatically adjust depth based on candidate responses.
3. When should you NOT share automated candidate feedback?
Sharing automated feedback sounds candidate-friendly, but it carries trade-offs worth weighing. In regulated industries or jurisdictions with AI hiring laws (e.g., NYC Local Law 144, Illinois AI Video Interview Act, EU AI Act), automated scoring rationale shared with candidates may become discoverable in adverse-action disputes — and any ambiguity in the rubric language becomes a legal exposure. Detailed feedback can also coach future candidates on how to game the rubric if leaked. The pragmatic middle ground: share high-level performance summaries and let recruiters deliver specific feedback verbally, where context and tone can be managed. Run any candidate-facing automated feedback past legal before turning it on.
4. How do you measure the ROI of AI interview screening for automation testing hires?
Track four metrics before and after implementation: time from application to shortlist, engineering hours spent on screening interviews, interview-to-offer ratio, and 90-day performance scores for new hires. The cumulative effect is recovered recruiter capacity and a meaningful reduction in hours engineering spends on first-round interviews — both of which can be measured directly inside your ATS reporting once the workflow has been in place for a full hiring cycle.
5. Can an AI interview agent screen for niche frameworks like Appium or Playwright?
Yes. The key is rubric specificity. If you are hiring for mobile automation, your rubric should include Appium-specific dimensions like device farm configuration, gesture handling, and hybrid app testing. Platforms with deep question libraries spanning a wide range of skills and programming languages support these niche configurations out of the box.
Editorial notes for publication:
- Meta title and description are not present in the draft and must be locked before publishing. Suggested meta title (under 60 chars): "How to Use an AI Interview Agent for Automation Testers". Suggested meta description: trim the opening definition sentence to ~155 characters.
- Target word count is a metadata constraint not addressed here; confirm the displayed "10 minutes" read time matches the final word count at 250 wpm before publishing.
- Verify all external links (Capterra, ITRC, SHRM, Tidio) are live and that cited figures match the linked sources. The ITRC reference has been softened pending confirmation that the 118% figure refers specifically to resume/application fraud rather than identity fraud broadly. The Schmidt & Hunter "2x" framing has been softened to a directional claim pending source confirmation.
- The "150M+ assessment signals" claim has been removed from the body pending proper attribution to a HackerEarth data page or named report with year anchor.
- Confirm OnScreen capability claims (real-time code evaluation mechanism, sandboxed IDE) with product before publication; the body has been softened to describe rubric-based evaluation generally rather than asserting OnScreen-specific behavior.
- The "Page Object Model" internal link in Step 1 was a placeholder pointing to the blog root and has been removed; replace with a specific article URL if one exists.