Fintech is the application of technologies to disrupt existing processes or bring in new paradigms in the financial industry. Be it banking or insurance or digital payment, fintech is currently revolutionizing the world.
Fintech has disrupted all aspects of the industry. Rapid innovation is the key in sectors like lending, financial inclusion, financial advisory, personal finance, security, and digital payments. Fintech, on one hand made services like Net Banking a given in today’s world. On the other hand, it has made names of startups like PayTM a common word in the vocabulary of the laymen.
Fintech companies are more customer centric than traditional financial companies. They believe in rapid innovation. The fact that many of the early adopters are low-age groups with disposable incomes has made fintech one of the hottest trends in technology.
What are the companies in fintech?
There are mainly four types of companies that are interested in fintech.
- Major banks that have traditionally been associated with finance and look at technology and fintech as the next level, for example, any large bank that has technology offerings
- Well-established tech players that are also looking for business opportunities in the financial services space although they are not traditionally financial companies, for example, we now have the Google wallet and the Apple pay.
- Companies that provide infrastructure and services which enable other fintech players to operate in the financial space; examples include PayUmoney that acts as a payments gateway, or MasterCard, which processes payments between banks of merchants when the merchants use the cards that are issued by the banks
Disruptors that are fast-moving companies and startups; these companies generally focus on a single business innovation or process. For example take SoFi, it is a San Francisco based company that focuses on high-earning recent graduates and tries to refinance their student loans. Or take the case of PayTM, which focuses on the Indian payments ecosystem.
What are the major fintech areas that are driving innovation?
Lending: Lending is the space where the biggest innovations in fintech are coming from. Traditionally, lenders have given more money to people who already have money. Fintech companies are doing away with the traditional credit history-based scoring system and coming up with lending solutions even for the unbanked. For example, Lending Club operates an online lending platform that helps borrowers get a loan and investors purchase notes backed by payments made on loans. Others like Biz2Credit are using social profiling tools to access the credit worthiness of individuals and small businesses.
Financial Inclusion: Experts believe that fintech is the key behind financial inclusion. For example, M-Pesa reached 80% of households in Kenya in 4 years[source]. Fintech companies achieve financial inclusion through various methods. One of them can be by leveraging existing low-cost solutions, like M-Pesa doing transactions through SMS. One other example is Kobocoin, which is giving an existing technology, blockchain in this case, a more local flavor so that it reflects the needs of the masses.
Even for developed countries, companies that focus on financial inclusion have the potential to make social security programs more effective. For example, in various parts of the world like Japan and India, public benefits are directly paid to the bank accounts of the recipients and the process is tracked through a Unique Identification Number like Aadhar Card in India or the My number(??????) system in Japan.
Financial Advisory: Fintech companies have generally relied on automation to provide services and this is the strategy being applied to traditional advisory services like M&A transactions, restructuring, raising capital, and forensic investigations. There can be a common platform where the users can engage with the experts as in BankerBhai.com. One more example is Elliptic, which provides services like identifying illicit activity on the Bitcoin blockchain.
Personal Finance: Through the use of fintech, there is a lot of scope to have more efficient processes. Many organisations are building companies by automating the acts of personal finance like individual or family budgeting, insurance, savings, and retirement planning. For example, Wealthfront provides online money management. Paytm tries to keep all your different payments under one portal.
Blockchain and distributed ledgers: Blockchain, which is the technology behind the famous bitcoin, is an open source distributed database using state-of-the-art cryptography. Currencies that use blockchain enable us to do transactions without a powerful third party like a bank or the government. There are various companies that are operating in the space of blockchain, either by using bitcoin, the largest blockchain, like Blockchain.info or Unocoin, or by having their own blockchain cryptocurrency like Kobocoin.
Security: Fintech is only projected to grow in the future and since this domain primarily deals in finance and financial products, customers will have high expectations in terms of security from fintech products. Also, fintech companies will always be a lucrative target for people with malicious intent. For example, there was the JP Morgan Chase data breach in 2014[source] which affected 83 million customers accounts. For this reason, heavy investment is being done in security. and we have a lot of companies in the field. For example, VKey focuses on user security. Tranwall is a Hong Kong startup that focuses on providing increased levels of security to the cardholders of the customer banks.

What is the future in fintech
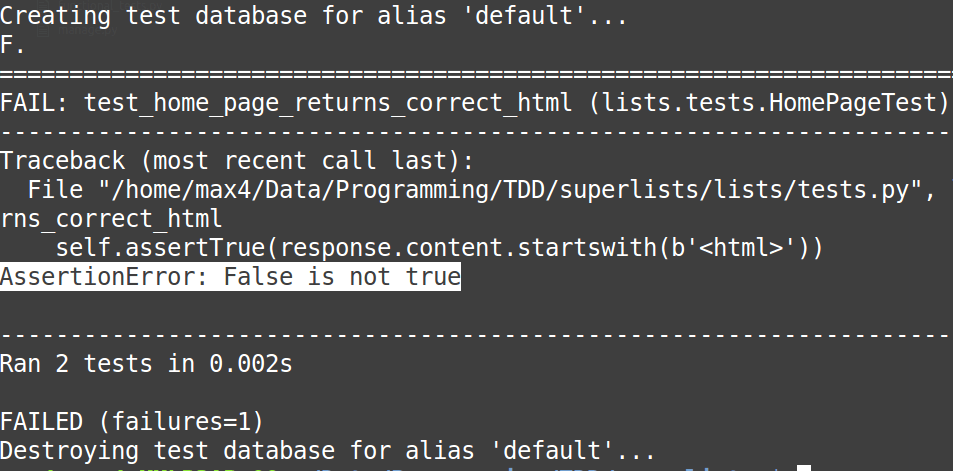
The rise in fintech has led to growth in both customer awareness and customer expectations, and this acts both as a challenge and as an opportunity. This has resulted in financial incumbents, those who are already established financial services players, taking bold steps and engaging with emerging innovations. Also, new start-ups have found greater acceptance with the population. Following graphs show the amount of investment the fintech companies have received globally.

Image: the growth of global investment in the fintech sector from 2011 to 2016
Source: Business Insider
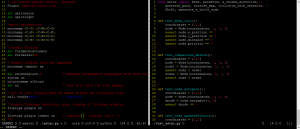
Users are also spending more time on various apps and doing a greater part of their financial transactions through the apps.

User activity on various payments apps
Source: Nielson
If you think that these trends are astonishing, remember that this will only grow in the coming years.
References:
techstory: lending market in india
letstalkpayments: 22 fintech companies in africa
fintech is the key driver of financial inclusion
fintech and financial inclusion
how fintech security helps foster innovation
fintech companies in fraud prevention
how banks are leveraging developer community