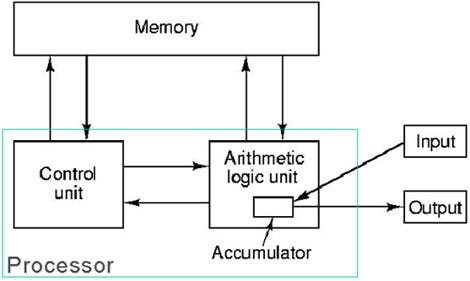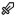
Have you ever understood the process of learning? How you learn how to perform a particular task? How do you learn to play a musical instrument? How do you learn social convention? How do you learn to lie? Apart from humans, plants and animals possess the ability to learn. And in recent times, so have machines.
Today machine learning is responsible for everything from Siri, Google Now, the recommendation engine on YouTube and Netflix, to even the driverless cars. Surely, machine learning is something that every computer scientist will encounter sooner or later, and it is important to learn this well.
History of Machine Learning
Machine learning was the byproduct of the early endeavours to develop artificial intelligence. The aim was to make a machine learn via data. But the use of this approach often resulted in reinventing already existing statistical models. This, coupled with the increase in knowledge and logical based approach to AI put machine learning out of favour among the AI community. Machine learning soon became a sub-sect of statistics and data mining.
But, over time, Machine Learning has become a separate field of its own. Instead of striving to achieve artificial intelligence, the main aim of machine learning has become more towards tackling solvable problems. It borrows techniques from statistics and probability to focus on predictions derived from data.
Machine Learning and AI
Ever since the rebirth of machine learning as its own field, there has been many a debate on the distinction between machine learning and AI.
There is one group that believes that machine learning is the only kind of AI there is. As machine learning enables a machine to learn based on external stimuli, it is in essence mapping the mind, which makes it the only kind of AI there is.
There are those who also believe that while machine learning is AI, AI is more than just machine learning. AI includes concepts like symbolic logic, evolutionary algorithms and Bayesian statistics and many other concepts that don’t fall under the purview of machine learning.
The important thing to note is the goals that each one of them try to achieve. Apart from machine learning, AI tries to achieve a broad range of goals like Reasoning, Knowledge representation, Automated planning and scheduling, Natural language processing, Computer vision, Robotics and General intelligence. Machine learning on the other hand focuses on solving tangible, domain specific problems through data and self learning algorithms.
So what are the skills you need to learn to get started with machine learning? Read on -
Seeing Is Believing
R2D3 has one of the best visual representations of what machine learning is. It takes the example of room sizes and elevations of homes in different cities in the US. This visual representation is a walkthrough of the techniques used to build an algorithm that will be able to predict the location of the house based on the dimensions of the rooms. Check out R2D3.
Another great resource is this blog on the Scikit learn site. In fact, at some point you will use Scikit learn, which is an open source machine learning library for the Python programming language.
Kaggle is one of the sites known for machine learning contests. This guide is a great starting point for anyone with a little bit of programming skills.
The Tongue
While most programmers prefer Python for its all-round capabilities and its data exploration prowess. However, the kind of programming language that you need to use depends on the machine learning application. This answer on Quora by a former Googler beautifully elucidated the process behind choosing a language while building your machine learning algorithm. Apart from Python, languages like C++, R and Java are popular among machine learning enthusiasts.
There are many libraries in Python for machine learning. Pybrain is one of them. As mentioned before, Scikit learn is another popular machine learning library in Python.
Key Skills
The language is only one of the many skills that you need to be adept at machine learning. You will need sound understanding of probability and statistics, applied mathematics and algorithms, distributed computing, big data and even signal processing techniques. Joseph Misiti, a data scientist at Square, explains the intricacies of each of these requisites.
This blog post on Udacity by a data scientist at Airbnb is a great post on the skills that a data scientist in today’s age is expected to have.
CMU has a free and open course on statistics for machine learning, with video lectures, assignments and solutions as well.
The Attitude
And lastly, and perhaps the most important trait that someone pursuing machine learning needs, is the attitude of a data scientist. This article from the Zipfian Academy elucidates the mindset that a good data scientist needs and this mindset goes a long way in being good with machine learning as well.
While you’re at it, you should also check out the machine learning track at IndiaHacks. It’s a fantastic opportunity to get your hands dirty with a real time machine learning problem and put yourself to test with some of the best talents in the machine learning space.