Times are changing and have been for a while now. In the world of STEM, women are no longer considered a “bad fit,” which is easily proved by the amazing number of brilliant women in the field today. Women are just as interested in finding out how things work, extracting insight from data, problem-solving, and helping businesses make the right decisions. Staggering amounts of data and knowing that it will only grow has paved the way for boundless opportunities for jobs related to data science, across both genders.
Disappointing Statistics in Favor
Despite being named the sexiest job of the century, data science seems to have few takers among the women folk. Following are some interesting stats about women in the technology domain:
- The American Association of University Women found that the percentage of women in math and computational jobs fell from 35% in 1990 to 26% in 2013.
- BetterBuys’ collated report shows that women make up about 26% of data professionals, with 39% researcher roles, 28% in creative roles, 18% in business management roles, and 13% in developer roles.
- In 2014, women held only 13% of the Chief Information Officer and 25% of Chief Data Officer positions. What is worse is that research found “women were two times more likely than men to quit high-tech positions.”
So, what’s stopping more women from getting into data science and analytics?
We don’t want people talking about gender gap in the world of technology and analytics anymore. Seriously, there is no conspiracy to keep women out of this typically male-dominated sphere. We need diversity in the boardroom, like now.

Why are women not "gung-ho" about such an exciting field?
Women often face challenges in the form of stereotypes and condescension, especially in developing countries like India, when trying to prove their worth. Cultural perception affects their self-confidence and chances of growth. You find women struggling to find work-life balance. Battling these undercurrents and the lack of adequate support and encouragement at home and workplace are sources of stress many talented women are choosing to do without.
Not an ideal situation…
But take heart, aspiring women data scientists. This is what Evenbrite’s Senior Data Scientist, Vesela Gateva, says:
Once you have a very genuine curiosity in a quantitative field or anything science-related, let your curiosity be your main guidance. You shouldn’t think that you’re a woman. I never aspired to be a data scientist. It’s a very recent term. I just ended up being one. All I knew was that I wanted to apply my quantitative skills, solving interesting problems. Women in general tend to give themselves less credit than they deserve. What women should know is that once they have the curiosity, and the basic fundamentals of probability and statistics, computer science, and machine learning, they can figure out the rest on their own.
Gender shouldn’t limit accomplishments, and it certainly shouldn’t define a person’s identity.
14 Women who've hit the stereotype out of the park
What aspiring women data scientists need are to look to bright women who have defied odds to rise to leadership positions in the field of analytics. No point in whining about lack of female representation if you are going to contribute, is there?
Let's appreciate these women for their work and incessant dedication which has helped millions of people around the world to inspire, learn and rise in their respective careers.
 Corinna Cortes, Google Research
Corinna Cortes, Google Research
She needs no introduction to people who in the world of Machine Learning. Corinna Cortes is the head of Google Research (NY), prior to which she was a distinguished researcher for a decade at AT&T Bell Labs. Her development of the algorithm, Support Vector Machines, fetched her the Paris Kanellakis Theory and Practice Award in 2008. She received her PhD in Computer Science in 1993 from the University of Rochester (NY) and has an MS in Physics from the University of Copenhagen. This amazing mother of two is a competitive runner as well. Read her latest tweets here.
 Daphne Koller, Co-founder, Coursera
Daphne Koller, Co-founder, Coursera
Israeli-American Daphne Koller is a leading expert in the field of machine learning, with special focus on probabilistic graphical models. She is the Chief Computing Officer at Calico Labs. Daphne is also the co-founder of the popular online education platform Coursera. She was a Stanford University professor of Computer Science for nearly two decades. Daphne Koller earned her PhD from Stanford, BS and MS from Hebrew University of Jerusalem, and has done her Post-doctoral research at UCLA. To view her many achievements, go here. When she’s not immersed in her work, you can find her spending time with her daughter or unwinding to music.
 Adele Cutler, Random Forest Algorithm Co-Developer
Adele Cutler, Random Forest Algorithm Co-Developer
Random Forests (a trademarked statistical classifier) co-developer Adele Cutler has a PhD from University of California, Berkeley, and a math degree from the University of Auckland. She’s been a statistics professor at Utah State University for almost three decades and continues her research in data mining and decision trees. She says, “As statisticians, what we’re really trying to do is think of better ways to get information out of data.” Adele Cutler has varied interests apart from math and stats, including spending time with her family in Taupo and Edinburgh, taking holidays, beading, and knitting. You can find more about her here.
 Jenn Wortman Vaughan, Microsoft Research
Jenn Wortman Vaughan, Microsoft Research
Jennifer Vaughan is a Senior Researcher at NYC-based Microsoft Research. She is interested in learning models and algorithms related to data aggregation. She received her PhD in 2009 in Computer and Information Science from the University of Pennsylvania, a Masters from Stanford in Computer Science, and a Bachelors in Computer Science from Boston University. She previously worked as an Assistant Professor (CS) in UCLA and was a Harvard University Computing Innovation Fellow. She has a handful of prestigious awards to her name, including a National Science Foundation CAREER award and a Presidential Early Career Award for Scientists and Engineers. In 2006, Jenn co-founded the Annual Workshop for Women in Machine Learning. If you want to know about this rising star, go to here website.
 Erin LeDell, Machine Learning Scientist, H2O.ai
Erin LeDell, Machine Learning Scientist, H2O.ai
California-based H2O.ai Machine Learning scientist, Erin LeDell has a doctorate in “Biostatistics and the Designated Emphasis in Computational Science and Engineering” from the University of California, Berkeley. She has a B.S. and M.A. in Mathematics. Her earlier work history includes working as the Principal Data Scientist at Wise.io and Marvin Mobile Security. Erin is also the founder of DataScientific, Inc. She has co-authored Subsemble: An Ensemble Method for Combining Subset-Specific Algorithm Fits. She is a co-founder of R-Ladies Global, an organization to encourage gender diversity in the R stats community. You can find Erin LeDell here.
 Jennifer Bryan, Associate Professor Statistics, UBC
Jennifer Bryan, Associate Professor Statistics, UBC
Jennifer Bryan is an Associate Professor, Statistics & Michael Smith Labs, at the University of British Columbia. She's a biostatistician specializing in genomics, and she enjoys statistical computing and data analysis. She has a BA in Economics from Yale and a doctoral degree from the University of California, Berkeley. She takes a popular introductory course in R. Look at her Twitter feed here.
 Hilary Mason, Founder, Fast Forward Labs
Hilary Mason, Founder, Fast Forward Labs
In her own words, “I love data and cheeseburgers!” Based in New York, Hilary Mason is the founder of Fast Forward Labs, a machine intelligence research company, and the Data Scientist in Residence at Accel. Her magic doesn’t end there. She co-hosts DataGotham, is a member of NYCResistor, and co-founded of HackNY. Apart from being featured in top publications like the Scientific American, she has received the TechFellows Engineering Leadership award and was on the Forbes 40 under 40 Ones to Watch list. She has co-authored Data Driven: Creating a Data Culture. For inspiration, you should look at her LinkedIn profile.
 Radhika Kulkarni, Vice President, Advanced Analytics R&D, SAS
Radhika Kulkarni, Vice President, Advanced Analytics R&D, SAS
Based in Durham, NC, Radhika Kulkarni is the Vice President, Advanced Analytics R&D, at SAS Institute Inc. She has a Masters in Mathematics from IIT-Delhi and a PhD in Operations Research from Cornell University. In her 30-year career with SAS, one of the foremost optimization software vendors, she has received many accolades—she is a SAS CEO Award of Excellence winner and chosen as one of the 100 Diverse Corporate Leaders in STEM by STEMconnector. She loves spending time with her three kids, and is very social. In her own words, “I'm well known to be the party animal.” Check out here tweets here.
 Alice Zheng, Senior Manager, Amazon
Alice Zheng, Senior Manager, Amazon
Alice Zheng is a Senior Manager of Applied Science at Amazon. She heads the optimization team on Amazon's Ad Platform. She was a Microsoft researcher for six years before her stint as the Director of Data Science at Dato. Her focus is on building scalable models in Machine Learning. She has undergraduate degrees in Computer Science and Math and a doctoral degree in electrical engineering from the University of California, Berkeley. Alice Zheng has written two books in the field of data science. She says, “My research focuses on easing the dependence on expertise by making learning algorithms more automated, their outputs more interpretable, and the labeling tasks simpler.” Look at her LinkedIn profile to read more interesting things about her.
 Charlotte Wickham, Assistant Professor Statistics, OSU
Charlotte Wickham, Assistant Professor Statistics, OSU
Charlotte Wickham works as an Assistant Professor of Statistics at the Oregon State University. An R specialist, she creates courseware for Data Camp. She has an Undergraduate degree in Statistics from the University of Auckland and a PhD in Statistics from the University of California, Berkeley. You can visit her website for more information.
Monica Rogati, Former Senior Data Scientist, LinkedIn
 Former VP of Data at Jawbone and LinkedIn senior data scientist, Monica Rogati is now an independent data science advisor. Her description on Medium is quite apt: Turning data into products and stories. Based in Sunnyvale, California, she has a PhD in Computer Science from the Carnegie Mellon University and a B.S. in computer science from the University of New Mexico. Her expertise lies in applied machine learning, text mining, and recommender systems. From wearable computing to developing a system to match a job to a candidate, she is an ace at it all. Her LinkedIn profile is chock-full of achievements. You can also follow her at @mrogati.
Former VP of Data at Jawbone and LinkedIn senior data scientist, Monica Rogati is now an independent data science advisor. Her description on Medium is quite apt: Turning data into products and stories. Based in Sunnyvale, California, she has a PhD in Computer Science from the Carnegie Mellon University and a B.S. in computer science from the University of New Mexico. Her expertise lies in applied machine learning, text mining, and recommender systems. From wearable computing to developing a system to match a job to a candidate, she is an ace at it all. Her LinkedIn profile is chock-full of achievements. You can also follow her at @mrogati.
 Alice Daish, Data Scientist, British Museum
Alice Daish, Data Scientist, British Museum
Alice Daish is a Data Scientist at the British Museum and a co-Founder of R-Ladies Global. She says, “I love data, R, science and innovation.” Her interests include data analysis, data visualization, predictive modelling, data communication, mentoring, and gender diversity in STEM.S he has a BSc. in Conservation Biology & Ecology from the University of Exeter and an MSc. in Quantitative Biology from Imperial College London. For a more detailed record of her projects and publications, go here. Follow Alice!
 Amy O'Connor, Big Data Evangelist, Cloudera
Amy O'Connor, Big Data Evangelist, Cloudera
Amy O'Connor is a Big Data evangelist at Cloudera. Prior to this, she was the Senior Director of the Big Data group at Nokia, and prior to that she was Senior Director of Strategy at Sun Microsystems. She describes herself as “a geek in high heels.” Amy O'Connor was on the Information Management’s “10 Big Data Experts to Know” in 2015. She has a BS in Electrical Engineering from the University of Connecticut and an MBA from Northeastern University. Follow her here.
 Julia Evans, Machine Learning Engineer, Stripe
Julia Evans, Machine Learning Engineer, Stripe
Montreal-based Julia Evans says “I love using serious systems in silly ways.” She has undergraduate and graduate degrees in Mathematics and Computer Science from McGill University. She works as a Machine Learning engineer at Stripe. She is passionate about programming and puts events together for women with similar interests. You can read for yourself here. Follow her interesting tweets here.
Women have great communication skills—a necessary skill when you need to tell decision makers what the results of the data analysis are. They are collaborative by nature—a key skill when people from different fields work together. They can think differently and tackle assumptions—vital skills when coupled with business acumen, stats, math, computer science, modeling, and analytical expertise. Admittedly men and women think differently. But that is what analysis is about, isn’t it? Different perspectives?
Like machine learning expert Claudia Perlich, Chief Scientist at Dstillery, said,
“Ultimately, data science is another technical field where women remain statistically a minority, but I do not believe that we need to force the issue or “fight” for a higher female quota. I want to come to work and do what I love and be recognized for what I bring to the table and not waste even one thought on the fact that I am female.”
So there really is no excuse for women to not enter this fascinating world of Data Science is there? Women just need to recognize that they have so much to bring to the table.
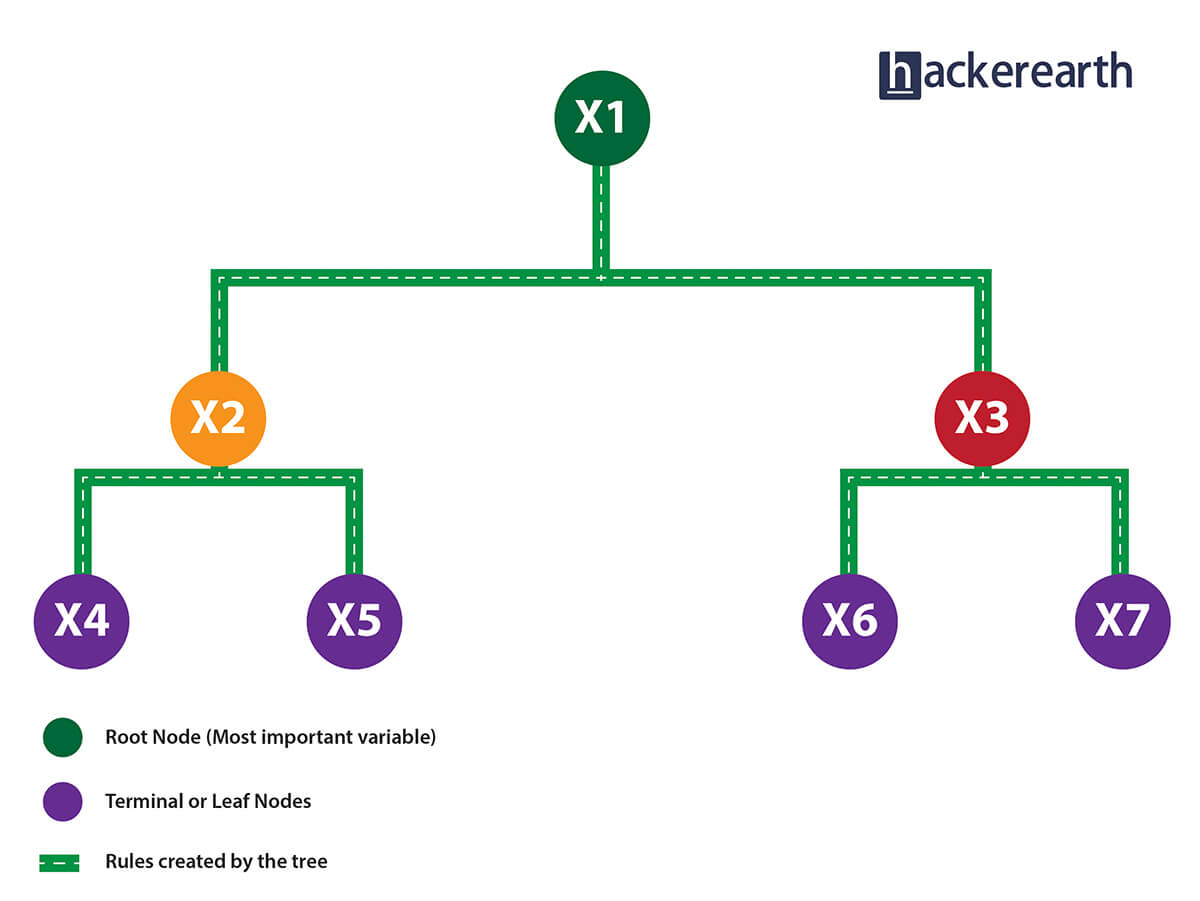
 Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.
Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.
























