



How to Hire Remote Developers: The 2026 Roadmap
The transformation of the global labor market has reached a critical inflection point in 2026, where the traditional, geography-bound hiring model has been largely superseded by a decentralized, remote-first paradigm. This shift is particularly evident in software engineering, a field uniquely suited to asynchronous collaboration and digital-native workflows. For engineering managers, CTOs, and HR leaders at growing technology firms, remote hiring is no longer a peripheral strategy for cost-cutting but a fundamental requirement for securing the specialized talent necessary to maintain a competitive edge.
The contemporary developer workforce increasingly views flexibility as a non-negotiable component of employment, with data indicating that a significant majority of job seekers prioritize remote options over traditional perks. Organizations that fail to adapt to this borderless reality find themselves restricted to localized talent pools that are rapidly shrinking, while competitors leveraging global sourcing strategies access a diverse array of experts across multiple continents.
The strategic imperative of global engineering talent
The transition toward distributed teams is underpinned by a confluence of economic and technological drivers that have matured significantly by 2026. The primary motivation for remote hiring has evolved from simple cost arbitrage to a comprehensive search for talent density. In the current landscape, the ability to hire the best engineer for a specific role, regardless of their physical location, allows organizations to solve complex technical challenges that were previously insurmountable due to regional skill shortages.
This strategic access is vital for scaling high-impact teams in specialized domains such as artificial intelligence, cloud architecture, and cybersecurity, where the demand for expertise far outstrips the supply available in any single metropolitan hub. Productivity metrics in 2026 continue to support the viability of remote models. Research indicates that remote workers often exhibit a notable increase in productivity compared to their in-office counterparts. This boost is attributed to the elimination of daily commutes, which saves employees an average of significant hours annually, and the reduction of office-based interruptions that frequently disrupt the deep-work cycles required for high-quality software development.
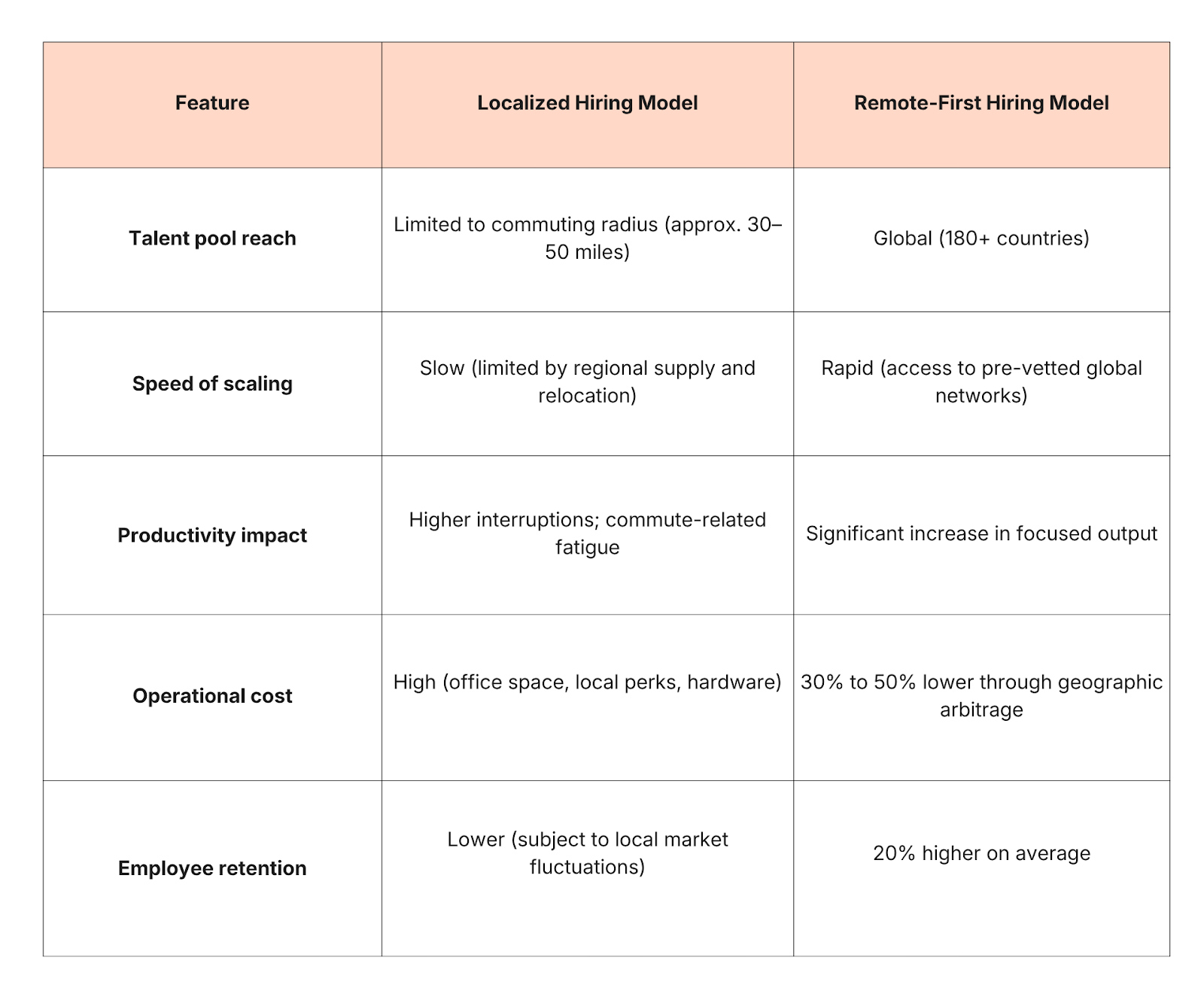
Furthermore, the financial benefits for the employer are substantial, with companies realizing average savings of approximately 10,000 to 15,000 per employee through reduced real estate overhead and infrastructure costs. The following table outlines the comparative advantages of the remote-first hiring model against the traditional localized approach as observed in 2026 market data.
Defining technical and operational roles in a distributed context
The foundation of a successful remote hiring process is the meticulous definition of the role, a task that carries greater weight in a distributed environment than in a centralized office. In the absence of physical proximity, ambiguity in job requirements often leads to misaligned expectations and costly hiring errors. Clarity must be established across technical proficiencies, autonomy levels, and collaboration protocols before the sourcing phase commences.
Technical requirements must be specified with precision, moving beyond generic titles like "Full-Stack Developer." Instead, descriptions should detail the specific languages, frameworks, and cloud infrastructures that are essential for the project's success. By 2026, proficiency in modern stacks such as React, Next.js, and Node.js, combined with expertise in containerization tools like Docker and Kubernetes, have become a standard requirement for many remote roles. Furthermore, as AI integration becomes ubiquitous, developers are increasingly expected to demonstrate "AI-adjacent" skills, which include the ability to work alongside automated agents and supervise AI-generated code.
Seniority and autonomy are perhaps the most critical indicators of success for a remote hire. The analysis suggests that remote developers must possess a higher degree of self-management than their in-office counterparts. Successful candidates in 2026 are those who can independently manage their development environments, debug complex issues without immediate supervision, and maintain momentum during asynchronous work cycles. This requirement for independence is particularly pronounced for junior-level roles, where the traditional "hand-holding" provided in an office setting is more difficult to replicate over digital channels.
Strategic Sourcing and the Taxonomy of Global Talent Hubs
Finding the right developers requires a multi-channel sourcing strategy that balances reach with candidate quality. In 2026, the sourcing landscape is divided between broad-reach job boards, specialized developer communities, and geographically targeted regional hubs. Organizations must select channels based on the specific technical niche and the desired level of experience.
Remote-focused job boards such as We Work Remotely and Remote OK remain the primary destination for companies seeking a wide pool of applicants who are already committed to the remote lifestyle. These platforms offer a global reach but require robust screening mechanisms to manage the high volume of applications. Conversely, developer communities like GitHub, GitLab, and Stack Overflow provide a more targeted approach. By reviewing public repositories and contributions, hiring managers can gain direct insight into a candidate's code quality, documentation style, and collaborative history before an initial interview is even scheduled.
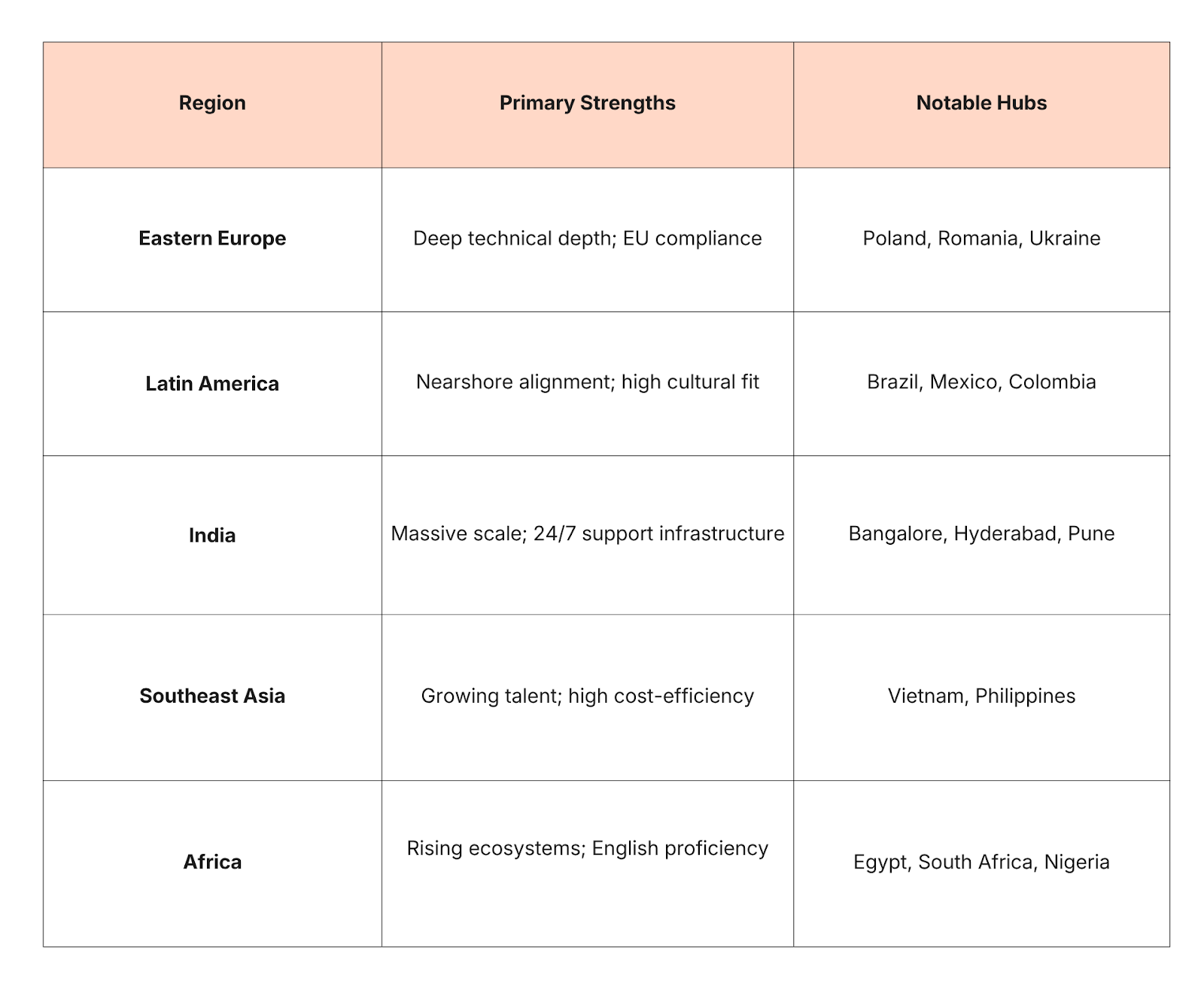
Regional hubs offer distinct advantages based on an organization's specific needs, such as cost efficiency, engineering depth, or time zone alignment. Latin America has emerged as a preferred destination for North American companies due to the minimal time zone difference, which facilitates real-time collaboration during core business hours. Countries like Brazil, Mexico, and Colombia are notable for their large talent pools and growing tech ecosystems. In contrast, Eastern Europe, particularly Poland, Romania, and Ukraine, is recognized for its deep engineering education and high proficiency in complex fields like fintech and cybersecurity.
Technical Assessment in a Remote Environment
The primary challenge in remote hiring is the verification of technical skills without the benefit of in-person interaction. Technical assessment have become a highly structured, multi-stage process that leverages AI to ensure fairness and accuracy. The assessment process begins with an asynchronous screening phase, followed by automated interviews and live collaborative coding sessions.
Asynchronous screening is used to filter high volumes of candidates efficiently. These tests typically focus on core language proficiency, algorithmic thinking, and practical problem-solving. To maintain the integrity of these remote exams, organizations employ advanced proctoring suites. These systems use AI to monitor for suspicious activities, such as navigating away from the test window, glancing off-screen, or receiving audio assistance. Features like the "Smart Browser" lock down the candidate's environment, preventing the use of virtual machines or screen-sharing tools to cheat.
The emergence of AI Interview Agents in 2026 has transformed the middle of the recruitment funnel. These agents conduct initial technical interviews using life-like video avatars, asking role-specific questions and adapting their follow-up queries based on the candidate's responses. This technology ensures that every candidate is evaluated against the same standard, significantly reducing the impact of unconscious bias. Furthermore, AI evaluation can save engineering managers up to 15 hours of manual interviewing per week, allowing them to focus on high-value architectural discussions with only the top-tier candidates.
Navigating Global Compliance and Employment Structures
International hiring requires a nuanced understanding of the legal and administrative frameworks that govern employment in different jurisdictions. Organizations must choose between three primary models: engaging independent contractors, partnering with an Employer of Record (EOR), or establishing a local legal entity. The decision hinges on the organization's headcount trajectory, risk tolerance, and long-term commitment to a specific region.
Engaging independent contractors is often the fastest way to onboard global talent. This model is ideal for short-term projects or for testing a new market before committing to a more permanent structure. However, the risk of "misclassification" is a significant concern in 2026. Regulatory bodies in countries like France and Italy have intensified their scrutiny of contractor relationships that mirror full-time employment. Misclassification can lead to substantial liabilities, with some estimates suggesting that the cumulative tax and penalty burden for a single misclassified worker can exceed 50,000 over three years.
Partnering with an Employer of Record (EOR) has become a standard strategy for mid-sized tech companies seeking to build stable, compliant teams across multiple countries. An EOR acts as the legal employer, managing payroll, local tax withholdings, and statutory benefits, while the client organization retains day-to-day operational direction. This model provides a "compliance-as-a-service" layer that shields the company from the complexities of local labor laws and enables them to offer competitive local benefits packages.
Compensation strategies and the 2026 salary landscape
Compensating remote developers fairly is a complex endeavor that requires balancing local market rates with global standards. In 2026, the trend has shifted toward "precision compensation," where salary budgets are surgically allocated to high-impact roles and specialized skills. Organizations generally adopt one of three compensation philosophies: location-based pay, role-based pay, or a hybrid model.
Location-based pay adjusts salaries based on the local cost of living and regional market benchmarks. This model allows companies to remain cost-effective and competitive within a specific geographic area. However, it can create internal resentment if developers in lower-cost regions feel their contributions are undervalued relative to peers in urban hubs. Role-based pay, conversely, standardizes compensation for a specific role regardless of the employee's location. This approach promotes equity and simplifies administration but can make it difficult for companies to compete for talent in high-cost cities like San Francisco or London.
A notable development in 2026 is the emergence of the "Presence Premium" and the "Flexibility Discount." As some organizations attempt to mandate a return to the office, roles requiring physical presence are commanding a 15% to 25% premium to offset commuting costs. Meanwhile, fully remote roles often reflect a flexibility discount, as many workers indicate they would accept a slight pay cut in exchange for the ability to work from anywhere. Furthermore, the value of AI literacy is quantified by a wage premium for developers who can demonstrate advanced skills in AI-assisted development.
Structural onboarding for distributed teams
Onboarding is the most frequent point of failure in the remote hiring lifecycle. Without the natural social integration provided by a physical office, remote onboarding must be engineered to provide clarity, connection, and a structured ramp-up period. The process should be divided into distinct phases, beginning well before the employee's first day and extending through their first 90 days of employment.
Before day one, the focus should be on logistics and information access. This includes shipping hardware to the employee's location at least a week in advance and ensuring all software licenses, VPN credentials, and system permissions are provisioned. Providing an "Onboarding Wiki" that details team hierarchies, communication protocols, and architectural documentation allows the new hire to begin absorbing context immediately. A "buddy system," where a peer is assigned to guide the new hire through the first few weeks, is essential for facilitating social connection and providing a low-pressure channel for asking critical questions.
The first week should focus on achieving "early wins" to build confidence. Assigning small, well-defined tasks that can be completed and shipped to production within the first few days provides the new hire with immediate feedback and a sense of accomplishment. Regular check-ins, ideally on a daily basis during the first week, prevent isolation and allow managers to address any early roadblocks. By the end of the first 90 days, the developer should be fully integrated into the team's rituals, contributing to major features, and operating with a high degree of autonomy.
Trust-based management and productivity in 2026
The long-term success of remote engineering teams depends on a shift from surveillance-based management to trust-based frameworks that prioritize output over activity. In 2026, traditional metrics such as "lines of code" or "hours logged" have been largely discredited as they fail to capture the true value delivered by a developer. Instead, leading organizations employ frameworks like SPACE and DORA to assess engineering health and individual performance.
The SPACE framework provides a multi-dimensional view of productivity, accounting for Satisfaction, Performance, Activity, Communication, and Efficiency. Similarly, DORA metrics focus on the velocity and stability of the software delivery pipeline, tracking indicators such as deployment frequency and the lead time for changes. These metrics are used to identify systemic bottlenecks rather than to rank individual developers, thereby protecting the psychological safety essential for high-performing teams.
Communication in 2026 is governed by "async-first" principles. This involves defaulting to written documentation, threaded discussions, and recorded video demos to ensure that information is accessible across all time zones without requiring real-time presence. Real-time meetings are reserved for complex problem-solving, strategic planning, or social bonding, ensuring that developers can maintain the large blocks of uninterrupted time—minimum 2 hours—required for deep-work focus.
The Future of Distributed Software Development
As the global workforce continues its digital transformation, the competitive advantage will lie with organizations that can effectively harness the power of distributed engineering. The most successful teams will be those that embrace "strategic talent density," hiring the best individuals regardless of zip code and empowering them with the tools and culture necessary to thrive in an asynchronous environment.
The shift toward remote work is not merely a logistical adjustment but a fundamental reimagining of the relationship between talent and opportunity. In this borderless era, the role of the engineering manager has evolved from a supervisor of presence to a facilitator of outcomes and a builder of global culture. Organizations that prioritize clarity in role definition, rigors in technical assessment, and trust in management will be best positioned to lead the next wave of technological innovation.