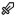At HackerEarth, we frequently send out emails to our user base. These are meant to keep them updated on upcoming challenges and on certain events related to their activity on our platform. For example, we send out emails when a user successfully solves a problem, whenever the user is sent a test invitation for a hiring challenge, or when there are new updates on his comments. Basically, whenever it is appropriate to convey important information to the user, we do it via email.
Architecture
It takes lot of computational power to send emails in such large quantities synchronously. So we implemented an asynchronous architecture to send emails.
Here is brief overview of the architecture:
- Construct an email and save the serialized email object in database.
- Queue the metadata for later consumption.
- Consume the metadata, recreate the email object, and deliver.
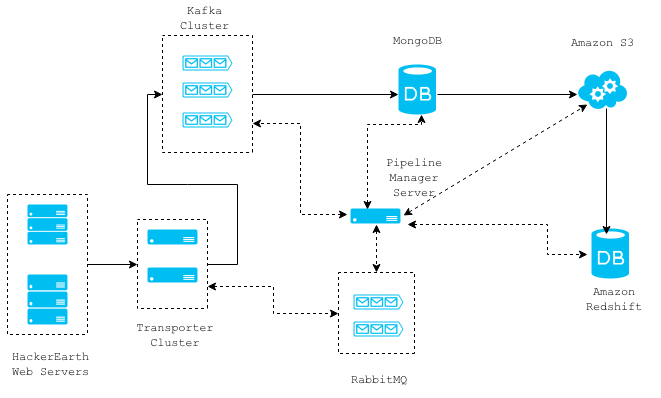
The diagram below shows the high-level architecture of emailing system. Solid lines represent the data flow between different components. Dotted lines represent the communications. HackerEarth email infrastructure consists of MySQL database, MongoDB database, and RabbitMQ queues.
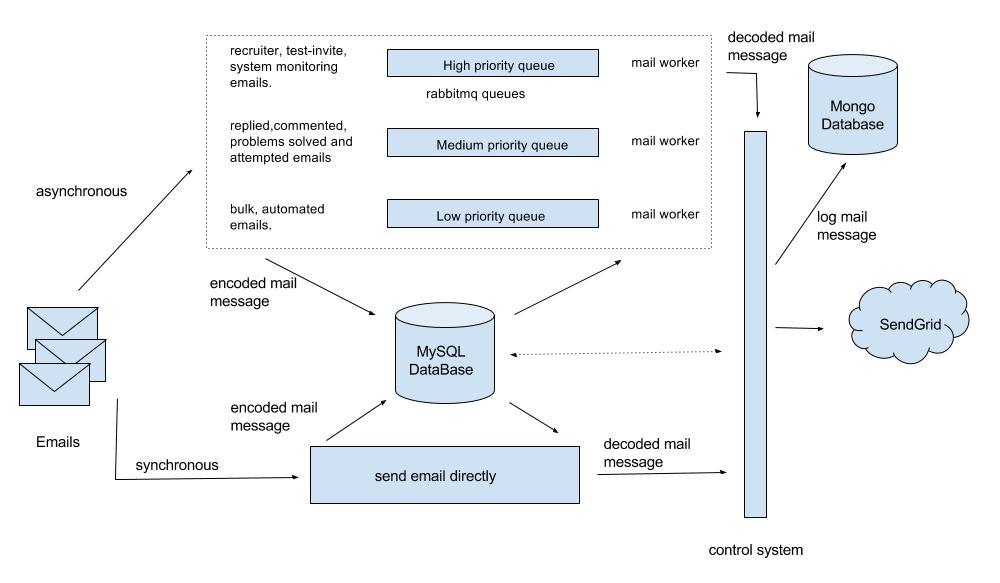
Journey Of Email
Step 1 - Construct email:
There are two different types of emails.
- Text - Plain text emails
- Html - Emails with rich interface using html elements, and made using django templates
API used by HackerEarth developers for sending emails:
send_email(ctx, template, subject, from_email, html=False, async=True, **kwargs)
The API above creates a SendGrid Mail object, serializes, and saves it in the DB with some additional data.
A piece of code similar to the bit shown below is used to create the SendGrid Mail object.
import sendgrid
sg = sendgrid.SendGridClient('YOUR_SENDGRID_API_KEY')
message = sendgrid.Mail()
message.add_to('John Doe <john@email.com>')
message.set_subject('Example')
message.set_html('Body')
message.set_text('Body')
message.set_from('Doe John <doe@email.com>')
status, msg = sg.send(message)
The model below is used to store the serialized mail object and additional data.
class Message():
# The actual data - a pickled sendgrid.Mail object
message_data = models.TextField()
when_added = models.DateTimeField(default=datetime.now, db_index=True)
After constructing and saving the email object in the database, metadata is queued in the RabbitMQ queues.
Step 2 - Queue the metadata:
Not all emails have the same importance in terms of delivery time. So we have created multiple queues to reduce the waiting time in queue for important mails.
- High priority queue
- Medium priority queue
- Low priority queue
It’s up to the application developer to decide the importance of the email and queue it in appropriate queue.
We queue the following metadata in the queue as a JSON object: {‘message_id’: 123}
Step 3 - Reconstruct and deliver:
We run delivery workers, which consume metadata from queues, reconstruct an email object, and deliver it using DMARC solution.
These workers consume the messages from RabbitMQ queues, fetch the message object from Message model, and deserialize the data to reconstruct the SendGrid Mail object.
We run different numbers of workers depending on the volume of emails in each queue.
Before sending an email, we do final checks which help us decide whether to deliver the email or not, such as if the email id is blacklisted or if the emails have non-zero number of receivers. This validation layer is especially important during using email warm up tools, where controlled sending and strict checks help build sender trust safely.
After a request is sent to SendGrid to deliver the email, the email objects are logged into a MongoDB to maintain the history of delivered emails.
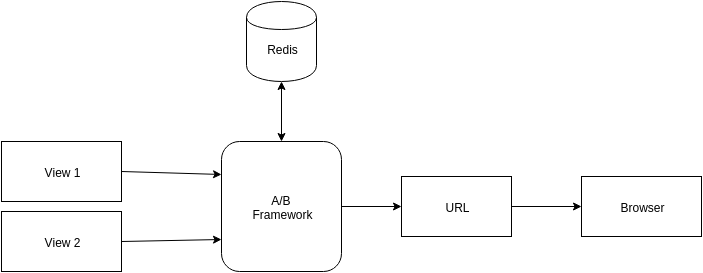
A/B Test In Emails
A million emails require optimization to improve user experience. This is done through A/B tests on emails type. We can test emails for subject and content variations. Every user on HackerEarth is assigned a bucket number to ensure emails are consistent during the experiment. Every A/B experiment is defined as dictionary mapped constants which contain all the information.
Here is one example of an A/B test with subject variation.
"""
EMAIL_VERSION_A_B
format of writing A/B test
key: test_email_type_version_number
value: email_dict
format for email_dict
keys: tuple(user_buckets)
values: category, subject, template
"""
EMAIL_VERSION_A_B = {
'A_B_TEST_1': {
tuple(user_bucket_numbers): {
'a_b_category': 'email_category_v1',
'subject': 'Hello hackerearth',
'template': 'emails/email.html'
},
tuple(user_bucket_numbers): {
'a_b_category': 'email_category_v2',
'subject': 'Welcome hackerearth',
'template': 'emails/email.html'
}
}
}
New experiments must update EMAIL_VERSION_A_B with experiment data. Information from EMAIL_VERSION_A_B is used to update the keyword arguments of HackerEarth sending email API (send_email). The category is propagated to update the category of SendGrid Mail object. Categories are used to see the variations in open rate and click rate for different A/B experiments.
Feel free to comment below or ping us at support@hackerearth.com if you have any suggestions!
This post was originally written for the HackerEarth Engineering blog by Kaushik Kumar.
Thanks to Pradeepkumar Gayam for improving it!