Data is key for making important business decisions. Depending upon the domain and complexity of the business, there can be many different purposes that a regression model can solve. It could be to optimize a business goal or find patterns that cannot be observed easily in raw data.
Even if you have a fair understanding of maths and statistics, using simple analytics tools you can only make intuitive observations. When more data is involved, it becomes difficult to visualize a correlation between multiple variables. You have to then rely on regression models to find patterns, which you can’t find manually, in the data.
In this article, we will explore different components of a data model and learn how to design a logistic regression model.
1. Logistic equation, DV, and IDVs
Before we start design a regression model, it is important to decide the business goal that you want to achieve with the analysis. It mostly revolves around minimizing or maximizing a specific (output) variable, which will be our Dependent variable (DV).
You must also understand the different metrics that are available or (in some cases) metrics that can be controlled to optimize the output. These metrics are called predictors or independent variables (IDVs).
A generalized linear regression equation can be represented as follows:
Y = β₀ + β₁X₁ + β₂X₂ + ... + βₚXₚ
where Xᵢ are the IDVs, βᵢ are the coefficients of the IDVs and β₀ is intercept.
This equation can be represented as follows:
Yᵢⱼ = Σₐ₌₁ᵖ Xᵢₐ βₐⱼ + eᵢⱼ
Logistic regression can be considered as a special case of linear regression where the DV is categorical or continuous. The output of this function is mostly probabilistic and lies between 0 to 1. Therefore, the equation of logistic regression can be represented in the exponential form as follows:
Y = 1 / (1 + e⁻ᶠ⁽ˣ⁾)
which is equivalent to:
Y = 1 / (1 + e⁻(β₀ + β₁X₁ + β₂X₂ + ... + βₚXₚ))
As you can see, the coefficients represent the contribution of the IDV to the DV. If Xᵢ is positive, then the high positive value increases the output probability whereas the high negative value of βᵢ decreases the output.
2. Identification of data
Once we fix our IDVs and DV, it is important to identify the data that is available at the point of decisioning. A relevant subset of this data can be the input of our equation, which will help us calculate the DV.
Two important aspects of the data are:
- Timeline of the data
- Mining the data
For example, if the data captures visits on a website, which has undergone suitable changes after a specific date, you might want to skip the past data for better decisioning. It is also important to rule out any null values or outliers, as required.
This can be achieved with a simple piece of code in R, which will have the following method:
Uploading the data from the .csv file and storing it as training.data. We shall use a sample data from imdb, which is available on Kaggle.
> training.data <- read.csv('movie_data.csv',header=T,na.strings=c(""))
> sapply(training.data,function(x) sum(is.na(x)))
color director_name num_critic_for_reviews duration director_facebook_likes
19 104 50 15 104
> training.data$imdb_score[is.na(training.data$imdb_score)] <- mean(training.data$imdb_score, na.rm=T)
You can also think of additional variables that can have a significant contribution to the DV of the model. Some variables may have a lesser contribution towards the final output. If the variables that you are thinking of are not readily available, then you can create them from the existing database.
When we are dealing with the non real-time data that we capture, we should be clear about how fast this data is captured so that it can provide a better understanding of the IDVs.
3. Analyzing the model
Building the model requires the following:
- Identifying the training data on which you can train your model
- Programming the model in any programming language, such as R, Python etc.
Once the model is created, you must validate the model and its efficiency on the existing data, which is of course different from the training data. To put it simply, it is estimating how your model will perform.
One efficient way of splitting the training and modelling data are the timelines. Assume that you have data from January to December, 2015. You can train the model on data from January to October, 2015. You can then use this model to determine the output on the data from November and December. Though you already know the output for November and December, you will still run the model to validate it.
You can arrange the data in chronological order and classify it as training and test data from the following array:
> train <- data[1:X,]
> test <- data[X:last_value,]
Fitting the model includes obtaining coefficients of each of the predictors, z-value, and P-value etc. It estimates how close the estimated values of the IDVs in the equation are when compared to the original values.
We use the glm() function in R to fit the model. Here's how you can use it. The 'family' parameter that is used here is 'binomial'. You can also use 'poisson' depending upon the nature of the DV.
> reg_model <- glm(Y ~., family=binomial(link='logit'), data=train)
> summary(reg_model)
> glm(formula = Y ~ ., family = binomial(link = "logit"), data = train)
Let's use the following dataset which has 3 variables:
> trees
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
...
Fitting the model using the glm() function:
> data(trees)
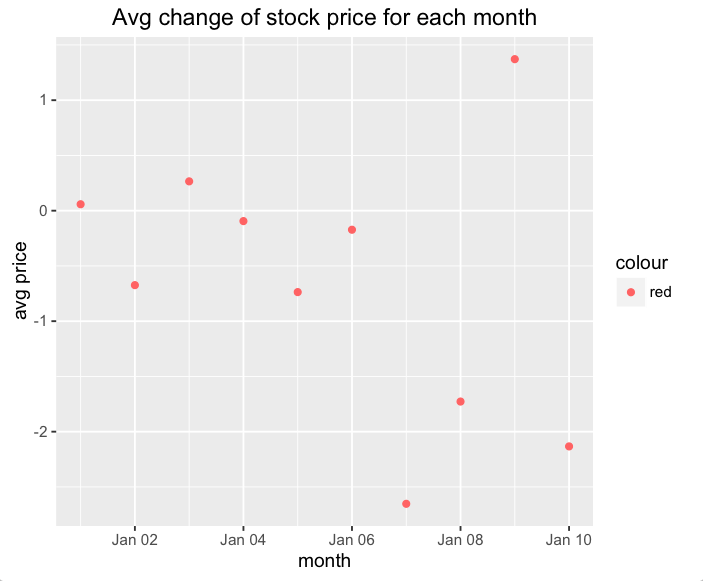
> plot(Girth~Volume, data=trees)
> abline(model)
> plot(Volume~Girth, data=trees)
> model <- glm2(vol ~ gir, family=poisson(link="identity"))
> abline(model)
> model
Call: glm2(formula = vol ~ gir, family = poisson(link = "identity"))
Coefficients:
(Intercept) gir
-30.874 4.608
Degrees of Freedom: 30 Total (i.e. Null); 29 Residual
Null Deviance: 247.3
Residual Deviance: 16.54 AIC: Inf
In this article, we have covered the importance of identifying the business objectives that should be optimized and the IDVs that can help us achieve this optimization. You also learned the following:
- Some of the basic functions in R that can help us analyze the model
- The
glm() function that is used to fit the model
- Finding the weights of the predictors with their standard deviation
In our next article, we will use larger data-sets and validate the model that we will build by using different parameters like the KS test.